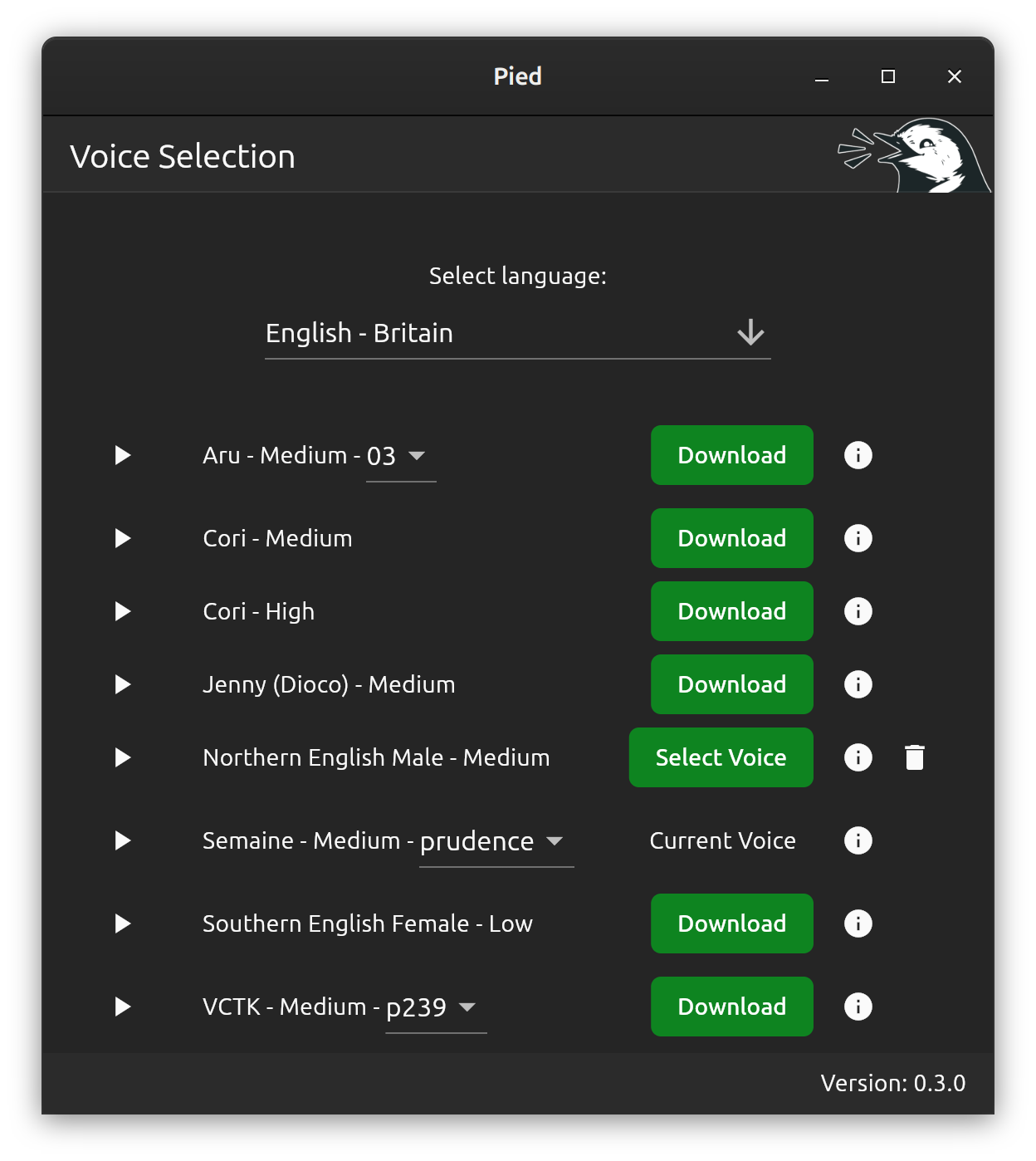
I’ve just released version 0.3 of Pied, my tool for making advanced text-to-speech voices work easily on Linux.
This release adds support for models with multiple sub-voices, providing access to hundreds of new voices. It also adds different qualities of model, fixes previews whilst downloading and fixes audio output detection when using sox.
All of us at Asymptotic are back home from the
exciting week at GStreamer Conference 2024 in Montréal, Canada last month. It was great to hang out with the community and see all the great work going on in the GStreamer ecosystem.
Montréal sunsets are
There were some visa-related adventures leading up to the conference, but
thanks to the organising team (shoutout to Mark Filion and Tim-Philipp Müller), everything was sorted out in time and Sanchayan and Taruntej were able to make it.
This conference was also special because this year marks the 25th anniversary of the GStreamer project!
Sanchayan spoke about his work with the various QUIC elements in GStreamer. We already have the quinnquicsrc and quinquicsink upstream, with a couple of plugins to allow (de)multiplexing of raw streams as well as an implementation or RTP-over-QUIC (RoQ). We’ve also started work on Media-over-QUIC (MoQ) elements.
This has been a fun challenge for us, as we’re looking to build out a general-purpose toolkit for building QUIC application-layer protocols in GStreamer. Watch this space for more updates as we build out more functionality, especially around MoQ.
Clock Rate Matching in GStreamer & PipeWire (video)
My talk was about an interesting corner of GStreamer, namely clock rate
matching. This is a part of live pipelines that is often taken for granted, so I wanted to give folks a peek under the hood.
The idea of doing this talk was was born out of some recent work we did to allow splitting up the graph clock in PipeWire from the PTP clock when sending AES67 streams on the network. I found the contrast between the PipeWire and GStreamer approaches thought-provoking, and wanted to share that with the community.
Next, Taruntej dove into how we optimised our usage of GStreamer in a real-time audio application on Windows. We had some pretty tight performance requirements for this project, and Taruntej spent a lot of time profiling and tuning the pipeline to meet them. He shared some of the lessons learned and the tools he used to get there.
Simplifying HLS playlist generation in GStreamer (video)
Sanchayan also walked us through the work he’s been doing to simplify HLS (HTTP Live Streaming) multivariant playlist generation. This should be a nice feature to round out GStreamer’s already strong support for generating HLS streams. We are also exploring the possibility of reusing the same code for generating DASH (Dynamic Adaptive Streaming over HTTP) manifests.
Hackfest
As usual, the conference was followed by a two-day hackfest. We worked on a few interesting problems:
Sanchayan addressed some feedback on the QUIC muxer elements, and then investigated extending the HLS elements for SCTE-35 marker insertion and DASH support
Taruntej worked on improvements to the threadshare elements, specifically to bring some ts-udpsrc element features in line with udpsrc
I spent some time reviewing a long-pending merge request to add soft-seeking support to the AWS S3 sink (so that it might be possible to upload seekable MP4s, for example, directly to S3). I also had a very productive conversation with George Kiagiadakis about how we should improve the PipeWire GStreamer elements (more on this soon!)
All in all, it was a great time, and I’m looking forward to the spring hackfest and conference in the the latter part next year!
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and a security fix
and it should be safe to update from 1.24.x.
(I worked on this feature last year, before being moved off desktop related projects, but I never saw it documented anywhere other than in the original commit messages, so here's the opportunity to shine a little light on a feature that could probably see more use)
The new usb_set_wireless_status() driver API function can be used by drivers of USB devices to export whether the wireless device associated with that USB dongle is turned on or not.
This will be used by user-space OS components to determine whether the
battery-powered part of the device is wirelessly connected or not,
allowing, for example:
- upower to hide the battery for devices where the device is turned off
but the receiver plugged in, rather than showing 0%, or other values
that could be confusing to users
- Pipewire to hide a headset from the list of possible inputs or outputs
or route audio appropriately if the headset is suddenly turned off, or
turned on
- libinput to determine whether a keyboard or mouse is present when its
receiver is plugged in.
This is not an attribute that is meant to replace protocol specific
APIs [...] but solely for wireless devices with
an ad-hoc “lose it and your device is e-waste” receiver dongle.
Currently, the only 2 drivers to use this are the ones for the Logitech G935 headset, and the Steelseries Arctis 1 headset. Adding support for other Logitech headsets would be possible if they export battery information (the protocols are usually well documented), support for more Steelseries headsets should be feasible if the protocol has already been reverse-engineered.
As far as consumers for this sysfs attribute, I filed a bug against Pipewire (link) to use it to not consider the receiver dongle as good as unplugged if the headset is turned off, which would avoid audio being sent to headsets that won't hear it.
UPower supports this feature since version 1.90.1 (although it had a bug that makes 1.90.2 the first viable release to include it), and batteries will appear and disappear when the device is turned on/off.
Early this month I spent a couple weeks in Montreal, visiting the city, but
mostly to attend the GStreamer Conference and the following hackfest, which
happened to be co-located with the XDC Conference. It was my first time in
Canada and I utterly enjoyed it. Thanks to all those from the GStreamer
community that organized and attended the event.
For now you can replay the whole streams of both days of conference, but soon
the split videos for each talk will be published:
GStreamer Conference 2024 - Day 1, Room 1 - October 7, 2024
The <video> element implementation in WebKit does its job by using a multiplatform player that relies on a platform-specific implementation. In the specific case of glib platforms, which base their multimedia on GStreamer, that’s MediaPlayerPrivateGStreamer.
The player private can have 3 buffering modes:
On-disk buffering: This is the typical mode on desktop systems, but is frequently disabled on purpose on embedded devices to avoid wearing out their flash storage memories. All the video content is downloaded to disk, and the buffering percentage refers to the total size of the video. A GstDownloader element is present in the pipeline in this case. Buffering level monitoring is done by polling the pipeline every second, using the fillTimerFired() method.
In-memory buffering: This is the typical mode on embedded systems and on desktop systems in case of streamed (live) content. The video is downloaded progressively and only the part of it ahead of the current playback time is buffered. A GstQueue2 element is present in the pipeline in this case. Buffering level monitoring is done by listening to GST_MESSAGE_BUFFERING bus messages and using the buffering level stored on them. This is the case that motivates the refactoring described in this blog post, what we actually wanted to correct in Broadcom platforms, and what motivated the addition of hysteresis working on all the platforms.
Local files: Files, MediaStream sources and other special origins of video don’t do buffering at all (no GstDownloadBuffering nor GstQueue2 element is present on the pipeline). They work like the on-disk buffering mode in the sense that fillTimerFired() is used, but the reported level is relative, much like in the streaming case. In the initial version of the refactoring I was unaware of this third case, and only realized about it when tests triggered the assert that I added to ensure that the on-disk buffering method was working in GST_BUFFERING_DOWNLOAD mode.
The current implementation (actually, its wpe-2.38 version) was showing some buffering problems on some Broadcom platforms when doing in-memory buffering. The buffering levels monitored by MediaPlayerPrivateGStreamer weren’t accurate because the Nexus multimedia subsystem used on Broadcom platforms was doing its own internal buffering. Data wasn’t being accumulated in the GstQueue2 element of playbin, because BrcmAudFilter/BrcmVidFilter was accepting all the buffers that the queue could provide. Because of that, the player private buffering logic was erratic, leading to many transitions between “buffer completely empty” and “buffer completely full”. This, it turn, caused many transitions between the HaveEnoughData, HaveFutureData and HaveCurrentData readyStates in the player, leading to frequent pauses and unpauses on Broadcom platforms.
So, one of the first thing I tried to solve this issue was to ask the Nexus PlayPump (the subsystem in charge of internal buffering in Nexus) about its internal levels, and add that to the levels reported by GstQueue2. There’s also a GstMultiqueue in the pipeline that can hold a significant amount of buffers, so I also asked it for its level. Still, the buffering level unstability was too high, so I added a moving average implementation to try to smooth it.
All these tweaks only make sense on Broadcom platforms, so they were guarded by ifdefs in a first version of the patch. Later, I migrated those dirty ifdefs to the new quirks abstraction added by Phil. A challenge of this migration was that I needed to store some attributes that were considered part of MediaPlayerPrivateGStreamer before. They still had to be somehow linked to the player private but only accessible by the platform specific code of the quirks. A special HashMap attribute stores those quirks attributes in an opaque way, so that only the specific quirk they belong to knows how to interpret them (using downcasting). I tried to use move semantics when storing the data, but was bitten by object slicing when trying to move instances of the superclass. In the end, moving the responsibility of creating the unique_ptr that stored the concrete subclass to the caller did the trick.
Even with all those changes, undesirable swings in the buffering level kept happening, and when doing a careful analysis of the causes I noticed that the monitoring of the buffering level was being done from different places (in different moments) and sometimes the level was regarded as “enough” and the moment right after, as “insufficient”. This was because the buffering level threshold was one single value. That’s something that a hysteresis mechanism (with low and high watermarks) can solve. So, a logical level change to “full” would only happen when the level goes above the high watermark, and a logical level change to “low” when it goes under the low watermark level.
For the threshold change detection to work, we need to know the previous buffering level. There’s a problem, though: the current code checked the levels from several scattered places, so only one of those places (the first one that detected the threshold crossing at a given moment) would properly react. The other places would miss the detection and operate improperly, because the “previous buffering level value” had been overwritten with the new one when the evaluation had been done before. To solve this, I centralized the detection in a single place “per cycle” (in updateBufferingStatus()), and then used the detection conclusions from updateStates().
So, with all this in mind, I refactored the buffering logic as https://commits.webkit.org/284072@main, so now WebKit GStreamer has a buffering code much more robust than before. The unstabilities observed in Broadcom devices were gone and I could, at last, close Issue 1309.
When you have a generational collector, you aim to trace only the part
of the object graph that has been allocated recently. To do so, you
need to keep a remembered set: a set of old-to-new edges, used as
roots when performing a minor collection. A language run-time maintains this set by
adding write barriers: little bits of collector code that run when a
mutator writes to a field.
Whippet’s nofl
space
is a block-structured space that is appropriate for use as an old
generation or as part of a sticky-mark-bit generational collector. It
used to have a card-marking write barrier; see my article diving into V8’s new
write
barrier,
for more background.
Unfortunately, when running whiffle
benchmarks, I was seeing no improvement for generational configurations relative to whole-heap collection. Generational collection
was doing fine in my tiny microbenchmarks that are part of Whippet
itself, but when translated to larger programs (that aren’t yet proper
macrobenchmarks), it was a lose.
I had planned on doing some serious tracing and instrumentation to
figure out what was happening, and thereby correct the problem. I still
plan on doing this, but instead for this issue I used the old noggin
technique instead: just, you know, thinking about the thing, eventually concluding that unconditional card-marking barriers are inappropriate
for sticky-mark-bit collectors. As I mentioned in the earlier article:
An unconditional card-marking barrier applies to stores to slots in
all objects, not just those in oldspace; a store to a new object will
mark a card, but that card may contain old objects which would then
be re-scanned. Or consider a store to an old object in a more dense
part of oldspace; scanning the card may incur more work than
needed. It could also be that Whippet is being too aggressive at
re-using blocks for new allocations, where it should be limiting
itself to blocks that are very sparsely populated with old objects.
That’s three problems. The second is well-known. But the first and
last are specific to sticky-mark-bit collectors, where pages mix old and
new objects.
a precise field-logging write barrier
Back in 2019, Steve Blackburn’s paper Design and Analysis of
Field-Logging Write
Barriers
took a look at the state of the art in precise barriers that record not
regions of memory that have been updated, but the precise edges (fields)
that were written to. He ends up re-using this work later in the 2022
LXR paper
(see §3.4), where the write barrier is used for deferred reference counting and a
snapshot-at-the-beginning (SATB) barrier for concurrent marking. All in
all field-logging seems like an interesting strategy. Relative to card-marking,
work during the pause is much less: you have a precise buffer of all
fields that were written to, and you just iterate that, instead of
iterating objects. Field-logging does impose some mutator cost, but perhaps the
payoff is worth it.
To log each old-to-new edge precisely once, you need a bit per field
indicating whether the field is logged already. Blackburn’s 2019 write
barrier paper used bits in the object header, if the object was small
enough, and otherwise bits before the object start. This requires some
cooperation between the collector, the compiler, and the run-time that I
wasn’t ready to pay for. The 2022 LXR paper was a bit vague on this
topic, saying just that it used “a side table”.
Iterability / interior pointers: is there an object at a given
address? If so, it will have a recognizable bit pattern.
End of object, to be able to sweep without inspecting the object
itself
Pinning, allowing a mutator to prevent an object from being
evacuated, for example because a hash code was computed from its
address
A hack to allow fully-conservative tracing to identify ephemerons at
trace-time; this re-uses the pinning bit, since in practice such
configurations never evacuate
Bump-pointer allocation into holes: the mark byte table serves the
purpose of Immix’s line mark byte table, but at finer granularity.
Because of this though, it is swept lazily rather than eagerly.
Generations. Young objects have a bit set that is cleared when they
are promoted.
Well. Why not add another thing? The nofl space’s granule size is two
words, so we can use two bits of the byte for field logging bits. If
there is a write to a field, a barrier would first check that the object
being written to is old, and then check the log bit for the field being
written. The old check will be to a byte that is nearby or possibly the
same as the one to check the field logging bit. If the bit is unsert,
we call out to a slow path to actually record the field.
preliminary results
I disassembled the fast path as compiled by GCC and got something like
this on x86-64, in AT&T syntax, for the young-generation test:
mov %rax,%rdx
and $0xffffffffffc00000,%rdx
shr $0x4,%rax
and $0x3ffff,%eax
or %rdx,%rax
testb $0xe,(%rax)
The first five instructions compute the location of the mark byte, from
the address of the object (which is known to be in the nofl space). If
it has any of the bits in 0xe set, then it’s in the old generation.
Then to test a field logging bit it’s a similar set of instructions. In
one of my tests the data type looks like this:
struct Node {
uintptr_t tag;
struct Node *left;
struct Node *right;
int i, j;
};
Writing the left field will be in the same granule as the object
itself, so we can just test the byte we fetched for the logging bit
directly with testb against $0x80. For right, we should be able
to know it’s in the same slab (aligned 4 MB region) and just add to the
previously computed byte address, but the C compiler doesn’t know that
right now and so recomputes. This would work better in a JIT. Anyway I
think these bit-swizzling operations are just lost in the flow of memory
accesses.
For the general case where you don’t statically know the offset of the
field in the object, you have to compute which bit in the byte to test:
mov %r13,%rcx
mov $0x40,%eax
shr $0x3,%rcx
and $0x1,%ecx
shl %cl,%eax
test %al,%dil
Is it good? Well, it improves things for my whiffle benchmarks,
relative to the card-marking barrier, seeing a 1.05×-1.5× speedup across
a range of benchmarks. I suspect the main advantage is in avoiding the
“unconditional” part of card marking, where a write to a new
object could cause old objects to be added to the remembered set. There are still quite a
few whiffle configurations in which the whole-heap collector outperforms
the sticky-mark-bit generational collector, though; I hope to understand
this a bit more by building a more classic semi-space nursery, and
comparing performance to that.
Implementation links: the barrier
fast-path,
the slow
path,
and the sequential store
buffers.
(At some point I need to make it so that allocating edge buffers in the
field set causes the nofl space to page out a corresponding amount of
memory, so as to be honest when comparing GC performance at a fixed heap
size.)
The GStreamer Conference team is pleased to announce that the full conference
schedule including talk abstracts and speaker biographies is now available for
this year's lineup of talks and speakers, covering again an exciting range of
topics!
The GStreamer Conference 2024 will take place on 7-8 October 2024
in Montréal, Canada, followed by a hackfest.
Details about the conference, hackfest and how to register can be found on the
conference website.
We hope to see you all in Montréal! Don't forget to register as soon as possible if you're planning on joining us, so we can order enough food and drinks!
Hey all, I had a fun bug this week and want to share it with you.
numbers and representations
First, though, some background. Guile’s numeric operations are defined over the complex numbers, not
over e.g. a finite field of integers. This is generally great when
writing an algorithm, because you don’t have to think about how the
computer will actually represent the numbers you are working on.
In practice, Guile will represent a small exact integer as a
fixnum,
which is a machine word with a low-bit tag. If an integer doesn’t fit
in a word (minus space for the tag), it is represented as a
heap-allocated bignum. But sometimes the compiler can realize that
e.g. the operands to a specific bitwise-and operation are within (say)
the 64-bit range of unsigned integers, and so therefore we can use
unboxed operations instead of the more generic functions that do
run-time dispatch on the operand types, and which might perform heap
allocation.
Unboxing is important for speed. It’s also tricky: under what
circumstances can we do it? In the example above, there is information
that flows from defs to uses: the operands of logand are known to be
exact integers in a certain range and the operation itself is closed over
its domain, so we can unbox.
But there is another case in which we can unbox, in which information
flows backwards, from uses to defs: if we see (logand n #xff), we know:
the result will be in [0, 255]
that n will be an exact integer (or an exception will be thrown)
we are only interested in a subset of n‘s bits.
Together, these observations let us transform the more general logand
to an unboxed operation, having first truncated n to a u64. And
actually, the information can flow from use to def: if we know that n
will be an exact integer but don’t know its range, we can transform the
potentially heap-allocating computation that produces n to instead
truncate its result to the u64 range where it is defined, instead of
just truncating at the use; and potentially this information could
travel farther up the dominator tree, to inputs of the operation that
defines n, their inputs, and so on.
needed-bits: the |0 of scheme
Let’s say we have a numerical operation that produces an exact integer,
but we don’t know the range. We could truncate the result to a u64
and use unboxed operations, if and only if only u64 bits are used. So
we need to compute, for each variable in a program, what bits are needed
from it.
I think this is generally known a needed-bits analysis, though both
Google and my textbooks are failing me at the moment; perhaps this is
because dynamic languages and flow analysis don’t get so much attention
these days. Anyway, the analysis can be local (within a basic block),
global (all blocks in a function), or interprocedural (larger than a
function). Guile’s is global. Each CPS/SSA variable in the function
starts as needing 0 bits. We then compute the fixpoint of visiting each
term in the function; if a term causes a variable to flow out of the
function, for example via return or call, the variable is recorded as
needing all bits, as is also the case if the variable is an operand to
some primcall that doesn’t have a specific needed-bits analyser.
Currently, only logand has a needed-bits analyser, and this is because
sometimes you want to do modular arithmetic, for example in a hash
function. Consider Bon Jenkins’ lookup3 string hash
function:
#define rot(x,k) (((x)<<(k)) | ((x)>>(32-(k))))
#define mix(a,b,c) \
{ \
a -= c; a ^= rot(c, 4); c += b; \
b -= a; b ^= rot(a, 6); a += c; \
c -= b; c ^= rot(b, 8); b += a; \
a -= c; a ^= rot(c,16); c += b; \
b -= a; b ^= rot(a,19); a += c; \
c -= b; c ^= rot(b, 4); b += a; \
}
...
(define (jenkins-lookup3-hashword2 str)
(define (u32 x) (logand x #xffffFFFF))
(define (shl x n) (u32 (ash x n)))
(define (shr x n) (ash x (- n)))
(define (rot x n) (logior (shl x n) (shr x (- 32 n))))
(define (add x y) (u32 (+ x y)))
(define (sub x y) (u32 (- x y)))
(define (xor x y) (logxor x y))
(define (mix a b c)
(let* ((a (sub a c)) (a (xor a (rot c 4))) (c (add c b))
(b (sub b a)) (b (xor b (rot a 6))) (a (add a c))
(c (sub c b)) (c (xor c (rot b 8))) (b (add b a))
...)
...))
...
These u32 calls are like the JavaScript |0
idiom,
to tell the compiler that we really just want the low 32 bits of the
number, as an integer. Guile’s compiler will propagate that information
down to uses of the defined values but also back up the dominator tree,
resulting in unboxed arithmetic for all of these operations.
All that was just prelude. So I said that needed-bits is a fixed-point
flow analysis problem. In this case, I want to compute, for each
variable, what bits are needed for its definition. Because of loops, we
need to keep iterating until we have found the fixed point. We use a
worklist to represent the conts we need to visit.
Visiting a cont may cause the program to require more bits from the
variables that cont uses.
Consider:
(define-significant-bits-handler
((logand/immediate label types out res) param a)
(let ((sigbits (sigbits-intersect
(inferred-sigbits types label a)
param
(sigbits-ref out res))))
(intmap-add out a sigbits sigbits-union)))
This is the sigbits (needed-bits) handler for logand when one of its
operands (param) is a constant and the other (a) is variable. It
adds an entry for a to the analysis out, which is an intmap from
variable to a bitmask of needed bits, or #f for all bits. If a
already has some computed sigbits, we add to that set via
sigbits-union. The interesting point comes in the sigbits-intersect
call: the bits that we will need from a are first the bits that we
infer a to have, by forward type-and-range analysis; intersected with
the bits from the immediate param; intersected with the needed bits
from the result value res.
If the intmap-add call is idempotent—i.e., out already contains
sigbits for a—then out is returned as-is. So we can check for a
fixed-point by comparing out with the resulting analysis, via eq?.
If they are not equal, we need to add the cont that defines a to the
worklist.
The bug? The bug was that we were not enqueuing the def of a, but
rather the predecessors of label. This works when there are no
cycles, provided we visit the worklist in post-order; and regardless, it
works for many other analyses in Guile where we compute, for each
labelled cont (basic block), some set of facts about all other labels
or about all other
variables.
In that case, enqueuing a predecessor on the worklist will cause all
nodes up and to including the variable’s definition to be visited,
because each step adds more information (relative to the analysis
computed on the previous visit). But it doesn’t work for this case,
because we aren’t computing a per-label analysis.
Does the fediverse have a vibe? I think that yes, there’s a flave, and
with reason: we have things in common. We all left Twitter, or refused
to join in the first place. Many of us are technologists or
tech-adjacent, but generally not startuppy. There is a pervasive do-it-yourself ethos. This last point often expresses itself as a
reaction: if you don’t like it, then do it yourself, a different way.
Make your own Mastoverse agent. Defederate. Switch instances. Fedi is
the “patches welcome” of community: just fork it!
Fedi is freedom, in the sense of “feel free to send a patch”, which is
also hacker-speak for “go fuck yourself”. We split; that’s our thing!
Which, you know, no-platform the nazis and terfs, of course. It can
be good and even necessary to cut ties with the bad. And yet, this is
not a strategy for winning. What’s worse, it risks creating a feedback
loop with losing, which is the topic of this screed.
alembics
Fedi distills losers: AI, covid, class war, climate, free software, on
all of these issues, the sort of people that fedi attracts are those
that lost. But, good news everyone: in fedi you don’t have to engage
with the world, only with fellow losers! I know. I include myself in
these sets. But beyond the fact that I don’t want to be a loser, it is
imperative that we win: we can’t just give up on climate or class war.
Thing is, we don’t have a plan to win, and the vibe I get from fedi is
much more disengaged than strategic.
Twitter—and I admit, I loved Twitter, of yore—Twitter is now for the
winners: the billionaires, the celebrities, the politicians. These
attract the shills, the would-be’s. But winner is just another word for
future has-been; nobody will gain power in the world via Twitter any
more. Twitter continues to be a formidable force, but it wanes by the
day.
Still, when I check my feed, there are some people I follow doing
interesting work on Twitter: consider Tobi
Haslett, Erin
Pineda, Bree
Newsome, Cédric
Herrou, Louis
Allday, Gabriel
Winant, Hamilton
Nolan, James
Butler, Serge
Slama: why there and not fedi? Sure,
there is inertia: the network was woven on Twitter, not the mastoverse.
But I am not sure that fedi is right for them, either. I don’t know
that fedi is the kind of loser that is ready to get back in the ring and
fight to win.
theories of power
What is fedi’s plan to win? If our model is so good, what are we
doing to make it a dominant mode of social discourse, of using it as a
vector to effect the changes we want to see in the world?
From where I sit, I don’t see that we have a strategy. Fedi is fine and
all, but it doesn’t scare anyone. That’s not good enough. Twitter was
always flawed but it was a great tool for activism and continues to be
useful in some ways. Bluesky has some of that old-Twitter vibe, and
perhaps it will supplant the original, in time; inshallah.
In the meantime, in fedi, I would like to suggest that with regards to
the network itself, that we stop patting ourselves on the back. What we
have is good but not good enough. We should aim to make the world a
better place and neither complacency nor splitting are going to get us there. If fedi is to thrive, we need to get out of our own heads and make our community a place to be afraid of.
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and it should be safe
to update from 1.24.x.
Highlighted bugfixes:
decodebin3: collection handling fixes
encodebin: Fix pad removal (and smart rendering in gst-editing-services)
glimagesink: Fix cannot resize viewport when video size changed in caps
matroskamux, webmmux: fix firefox compatibility issue with Opus audio streams
mpegtsmux: Wait for data on all pads before deciding on a best pad unless timing out
splitmuxsink: Override LATENCY query to pretend to downstream that we're not live
video: QoS event handling improvements
voamrwbenc: fix list of bitrates
vtenc: Restart encoding session when certain errors are detected
wayland: Fix ABI break in WL context type name
webrtcbin: Prevent crash when attempting to set answer on invalid SDP
cerbero: ship vp8/vp9 software encoders again, which went missing in 1.24.7; ship transcode plugin
Various bug fixes, memory leak fixes, and other stability and reliability improvements
Greetings, gentle readers. Today, an update on recent progress in the
Whippet embeddable garbage
collection library.
feature-completeness
When I started working on Whippet, two and a half years ago already, I
was aiming to make a new garbage collector for
Guile. In the beginning I was just
focussing on proving that it would be advantageous to switch, and also
learning how to write a GC. I put off features like
ephemerons and heap
resizing
until I was satisfied with the basics.
Well now is the time: with recent development, Whippet is finally
feature-complete! Huzzah! Now it’s time to actually work on getting it
into Guile. (I have some performance noodling to do before then, adding
tracing support, and of course I have lots of ideas for different
collectors to build, but I don’t have any missing features at the
current time.)
heap resizing
When you benchmark a garbage collector (or a program with garbage
collection), you generally want to fix the heap size. GC overhead goes
down with more memory, generally speaking, so you don’t want to compare
one collector at one size to another collector at another size.
(Unfortunately, many (most?) benchmarks of dynamic language run-times
and the programs that run on them fall into this trap. Imagine you are
benchmarking a program before and after a change. Automatic heap sizing
is on. Before your change the heap size is 200 MB, but after it is 180
MB. The benchmark shows the change to regress performance. But did it
really? It could be that at the same heap size, the change improved
performance. You won’t know unless you fix the heap size.)
Anyway, Whippet now has an implementation of
MemBalancer.
After every GC, we measure the live size of the heap, and compute a new
GC speed, as a constant factor to live heap size. Every second, in a
background thread, we observe the global allocation rate. The heap size
is then the live data size plus the square root of the live data size
times a factor. The factor has two components. One is constant, the
expansiveness of the heap: the higher it is, the more room the program
has. The other depends on the program, and is computed as the square
root of the ratio of allocation speed to collection speed.
With MemBalancer, the heap ends up getting resized at every GC, and via
the heartbeat thread. During the GC it’s easy because it’s within the
pause; no mutators are running. From the heartbeat thread, mutators are
active: taking the heap lock prevents concurrent resizes, but mutators
are still consuming empty blocks and producing full blocks. This works
out fine in the same way that concurrent mutators is fine: shrinking
takes blocks from the empty list one by one, atomically, and returns
them to the OS. Expanding might reclaim paged-out blocks, or allocate
new slabs of blocks.
However, even with some exponentially weighted averaging on the speed
observations, I have a hard time understanding whether the algorithm is
overall a good thing. I like the heartbeat thread, as it can reduce
memory use of idle processes. The general square-root idea sounds nice
enough. But adjusting the heap size at every GC feels like giving
control of your stereo’s volume knob to a hyperactive squirrel.
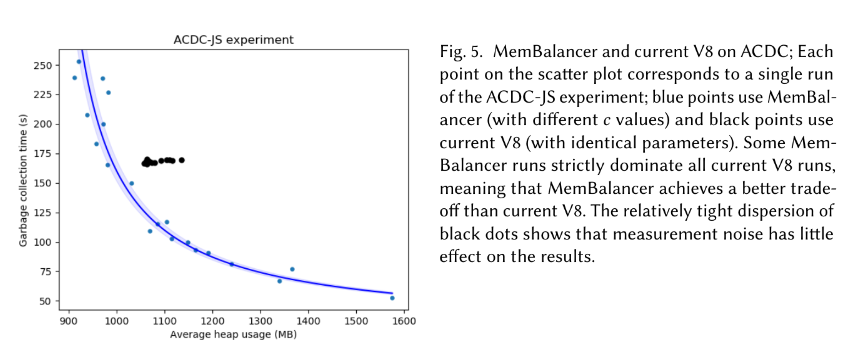
Figure 5 from the MemBalancer paper
Furthermore, the graphs in the MemBalancer
paper are not clear to me: the paper
claims more optimal memory use even in a single-heap configuration, but
the x axis of the graphs is “average heap size”, which I understand to
mean that maximum heap size could be higher than V8’s maximum heap size,
taking into account more frequent heap size adjustments. Also, some
measurement of total time would have been welcome, in addition to the
“garbage collection time” on the paper’s y axis; there are cases where
less pause time doesn’t necessarily correlate to better total times.
deferred page-out
Motivated by MemBalancer’s jittery squirrel, I implemented a little
queue for use in paging blocks in and out, for the
mmc
and
pcc
collectors: blocks are quarantined for a second or two before being
returned to the OS via madvise(MADV_DONTNEED). That way if you
release a page and then need to reacquire it again, you can do so
without bothering the kernel or other threads. Does it matter? It
seems to improve things marginally and conventional wisdom says to not
mess with the page table too much, but who knows.
mmc rename
Relatedly, Whippet used to be three things: the project itself,
consisting of an API and a collection of collectors; one specific
collector; and one specific space within that collector. Last time I
mentioned that I renamed the whippet space to the nofl
space.
Now I finally got around to renaming what was the whippet collector as
well: it is now the mostly-marking collector, or
mmc.
Be it known!
Also as a service note, I removed the “serial copying collector”
(scc). It had the same performance as the parallel copying collector
with parallelism=1, and pcc can be compiled with GC_PARALLEL=0 to
explicitly choose the simpler serial grey-object worklist.
per-object pinning
The nofl space has always supported pinned objects, but it was never
exposed in the API. Now it is!
Of course, collectors with always-copying spaces won’t be able to pin
objects. If we want to support use of these collectors with embedders
that require pinning, perhaps because of conservative root scanning,
we’d need to switch to some kind of mostly-copying
algorithm.
safepoints without allocation
Another missing feature was a safepoint API. It hasn’t been needed up
to now because my benchmarks all allocate, but for programs that have
long (tens of microseconds maybe) active periods without allocation, you
want to be able to stop them without waiting too long. Well we have
that exposed in the API now.
removed ragged stop
Following on my article on ragged
stops,
I removed ragged-stop marking from mmc, for a nice net 180 line
reduction
in some gnarly code. Speed seems to be similar.
next up: tracing
And with that, I’m relieved to move on to the next phase of Whippet
development. Thanks again to NLnet
for their support of this work. Next up, adding fine-grained tracing,
so that I can noodle a bit on performance. Happy allocating!
The GStreamer team is pleased to announce another release of liborc,
the Optimized Inner Loop Runtime Compiler, which is used for SIMD acceleration
in GStreamer plugins such as audioconvert, audiomixer, compositor, videoscale,
and videoconvert, to name just a few.
This is a bug-fix release, with some minor follow-ups to the security fixes of the previous release.
Highlights:
Security: Minor follow-up fixes for CVE-2024-40897
Fix include header use from C++
orccodemem: Assorted memory mapping fixes
powerpc: fix div255w which still used the inexact substitution
powerpc: Disable VSX and ISA 2.07 for Apple targets
powerpc: Allow detection of ppc64 in Mac OS
x86: work around old GCC versions (pre 9.0) having broken xgetbv implementationsv
x86: consider MSYS2/Cygwin as Windows for ABI purposes only
x86: handle unnatural and misaligned array pointers
x86: Fix non-C11 typedefs
x86: try fixing AVX detection again by adding check for XSAVE
Should your garbage collector be precise or conservative? The
prevailing wisdom is that precise is always better. Conservative GC can
retain more objects than strictly necessary, making GC slow: GC has to
more frequently, and it has to trace a larger heap on each collection.
However the calculus is not as straightforward as most people think, and
indeed there are some reasons to expect that conservative root-finding
can result in faster systems.
(I have made / relayed some of these arguments before but I feel like a
dedicated article can make a contribution here.)
problem precision
Let us assume that by conservative GC we mean conservative
root-finding, in which the collector assumes that any integer on the
stack that happens to be a heap address indicates a reference on the
object containing that address. The address doesn’t have to be at the
start of the object. Assume that objects on the heap are traced
precisely; contrast to BDW-GC which generally traces both the stack and
the heap conservatively. Assume a collector that will pin referents of
conservative roots, but in which objects not referred to by a
conservative root can be moved, as in Conservative
Immix or Whippet’s
stack-conservative-mmc
collector.
With that out of the way, let’s look at some reasons why conservative GC
might be faster than precise GC.
smaller lifetimes
A compiler that does precise root-finding will typically output a
side-table indicating which slots in a stack frame hold references to
heap objects. These lifetimes aren’t always precise, in the sense that
although they precisely enumerate heap references, those heap references
might actually not be used in the continuation of the stack frame. When
GC occurs, it might mark more objects as live than are actually live,
which is the imputed disadvantage of conservative collectors.
This is most obviously the case when you need to explicitly register
roots with some kind of handle API: the handle will typically be kept
live until the scope ends, but that might be an overapproximation of
lifetime. A compiler that can assume conservative stack scanning may
well exhibit more precision than it would if it needed to emit stack
maps.
no run-time overhead
For generated code, stack maps are great. But if a compiler needs to
call out to C++ or something, it needs to precisely track roots in a
run-time data
structure.
This is overhead, and conservative collectors avoid it.
smaller stack frames
A compiler may partition spill space on a stack into a part that
contains pointers to the heap and a part containing numbers or other
unboxed data. This may lead to larger stack sizes than if you could
just re-use a slot for two purposes, if the lifetimes don’t overlap. A
similar concern applies for compilers that partition registers.
no stack maps
The need to emit stack maps is annoying for a compiler and makes
binaries bigger. Of course it’s necessary for precise roots. But then
there is additional overhead when tracing the stack: for each frame on
the stack, you need to look up the stack map for the return
continuation, which takes time. It may be faster to just test if words
on the stack might be pointers to the heap.
unconstrained compiler
Having to make stack maps is a constraint imposed on the compiler.
Maybe if you don’t need them, the compiler could do a better job, or you
could use a different compiler entirely. A conservative compiler can sometimes have better codegen, for example by the use of interior pointers.
anecdotal evidence
The Conservative Immix
paper shows that conservative stack scanning can beat precise scanning
in some cases. I have reproduced these results with
parallel-stack-conservative-mmc compared to
parallel-mmc.
It’s small—maybe a percent—but it was a surprising result to me and I
thought others might want to know.
When it comes to designing a system with GC, don’t count out
conservative stack scanning; the tradeoffs don’t obviously go one way or the other, and conservative scanning might be the right engineering choice for your system.
Many years ago I read one of those Cliff Click “here’s
what I learned” articles in which he was giving advice about garbage
collector design, and one of the recommendations was that at a GC pause,
running mutator threads should cooperate with the collector by identifying roots from
their own stacks. You can read a similar assertion in their VEE2005
paper, The Pauseless GC
Algorithm,
though this wasn’t the source of the information.
One motivation for the idea was locality: a thread’s
stack is already local to a thread. Then specifically in the context of
a pauseless collector, you need to avoid races between the collector and
the mutator for a thread’s stack, and having the thread visit its own
stack neatly handles this problem.
However, I am not so interested any more in (so-called) pauseless collectors;
though I have not measured myself, I am convinced enough by the
arguments in the Distilling the real costs of production garbage
collectors
paper, which finds that state of the art pause-minimizing collectors
actually increase both average and p99 latency, relative to a
well-engineered collector with a pause phase. So, the racing argument
is not so relevant to me, because a pause is happening anyway.
There was one more argument that I thought was interesting, which was
that having threads visit their own stacks is a kind of cheap
parallelism: the mutator threads are already there, they might as well
do some work; it could be that it saves time, if other threads
haven’t seen the safepoint yet. Mutators exhibit a ragged stop, in
the sense that there is no clean cutoff time at which all mutators stop
simultaneously, only a time after which no more mutators are running.
Or so I thought! Let’s try to look at the problem analytically.
Consider that you have a system with N processors, a stop-the-world GC
with N tracing threads, and M mutator threads. Let’s assume that we
want to minimize GC latency, as defined by the time between GC is
triggered and the time that mutators resume. There will be one
triggering thread that causes GC to begin, and then M–1 remote
threads that need to reach a safepoint before the GC pause can begin.
The total amount of work that needs to be done during GC can be broken
down into rootsi, the time needed to visit roots for mutator
i, and then graph, the time to trace the transitive closure of live
objects. We want to know whether it’s better to perform rootsi during
the ragged stop or in the GC pause itself.
Let’s first look to the case where M is 1 (just one mutator thread).
If we visit roots before the pause, we have
Which is to say, thread 0 triggers GC,
visits its own roots, then enters the pause in which the whole graph is
traced by all workers with maximum parallelism. It may be that graph
tracing doesn’t fully parallelize, for example if the graph has a long
singly-linked list, but the parallelism with be maximal within the pause
as there are N workers tracing the graph.
If instead we visit roots within the pause, we have:
This is strictly better than the ragged-visit latency.
If we have two threads, then we will need to add in some delay,
corresponding to the time it takes for remote threads to reach a
safepoint. Let’s assume that there is a maximum period (in terms of
instructions) at which a mutator will check for
safepoints. In
that case the worst-case delay will be a constant, and we add it on to
the latency. Let us assume also there are more than two threads
available. The marking-roots-during-the-pause case it’s easiest to
analyze:
In this case, a ragged visit could win: while the triggering thread is
waiting for the remote thread to stop, it could perform
roots0, moving the work out of the pause, reducing pause
time, and reducing latency, for free.
However, we only have this win if the root-visiting time is smaller than
the safepoint delay; otherwise we are just prolonging the pause. Thing
is, you don’t know in general. If indeed the root-visiting time is
short, relative to the delay, we can assume the roots elements of our
equation are 0, and so the choice to mark during ragged stop doesn’t
matter at all! If we assume instead that root-visiting time is long,
then it is suboptimally parallelised: under-parallelised if we have more
than M cores, oversubscribed if M is greater than N, and
needlessly serializing before the pause while it waits for the last
mutator to finish marking its roots. What’s worse, root-visiting actually slows down delay, because the oversubscribed threads compete with visitation for CPU time.
So in summary, I plan to switch away from doing GC work during the ragged stop. It is complexity that doesn’t pay. Onwards and upwards!
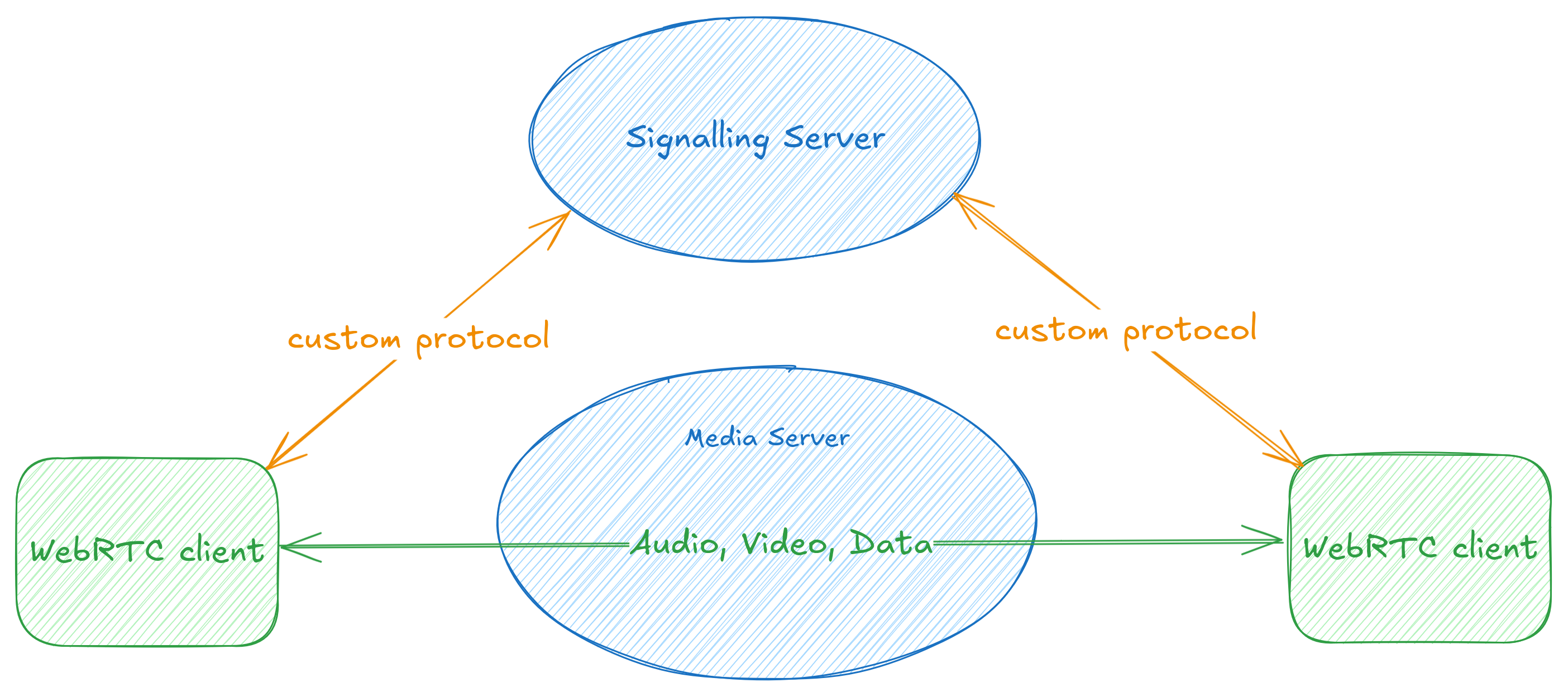
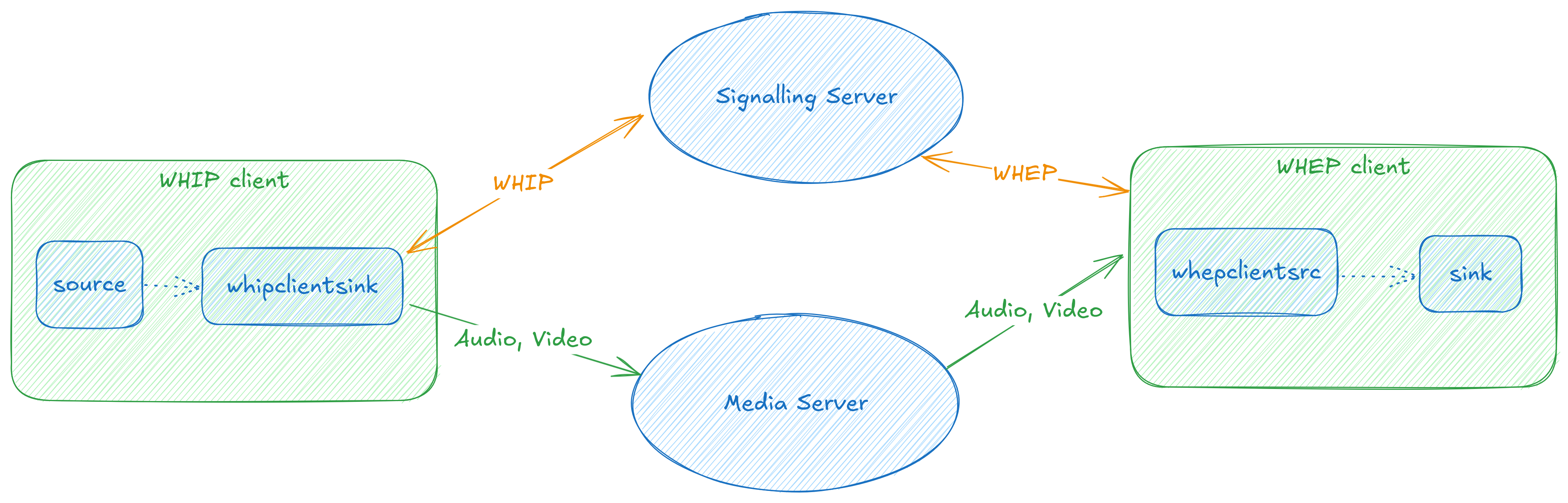
The WebRTC nerds among us will remember the first thing we learn about WebRTC, which is that it is a specification for peer-to-peer communication of media and data, but it does not specify how signalling is done.
Or put more simply, if you want call someone on the web, WebRTC tells you how you can transfer audio, video and data, but it leaves out the bit about how you make the call itself: how do you locate the person you’re calling, let them know you’d like to call them, and a few following steps before you can see and talk to each other.
WebRTC signalling
While this allows services to provide their own mechanisms to manage how WebRTC calls work, the lack of a standard mechanism means that general-purpose applications need to individually integrate each service that they want to support. For example, GStreamer’s webrtcsrc and webrtcsink elements support various signalling protocols, including Janus Video Rooms, LiveKit, and Amazon Kinesis Video Streams.
However, having a standard way for clients to do signalling would help developers focus on their application and worry less about interoperability with different services.
(author’s note: the puns really do write themselves :))
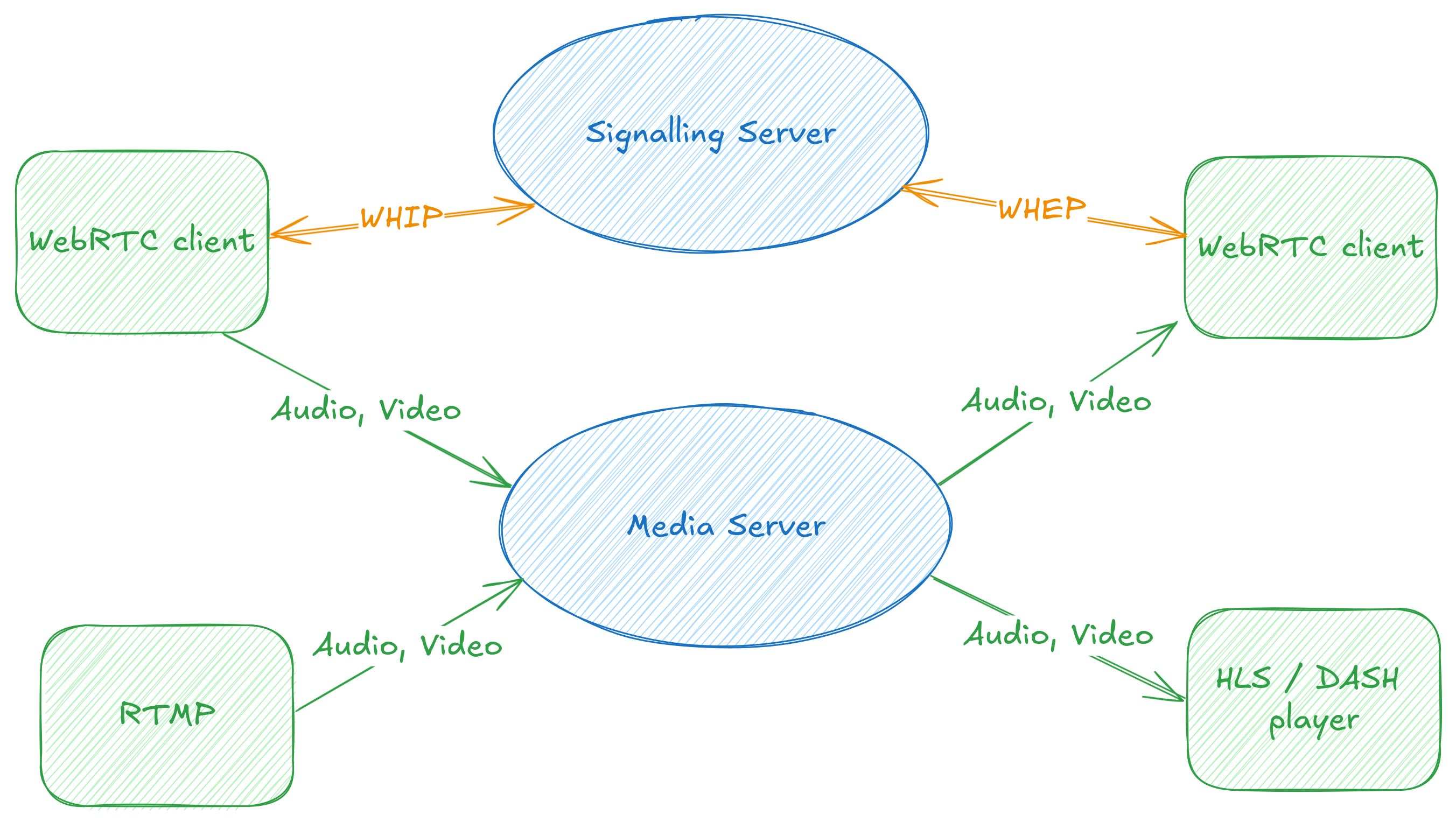
As the names suggest, the specifications provide a way to perform signalling using HTTP. WHIP gives us a way to send media to a server, to ingest into a WebRTC call or live stream, for example.
Conversely, WHEP gives us a way for a client to use HTTP signalling to consume a WebRTC stream – for example to create a simple web-based consumer of a WebRTC call, or tap into a live streaming pipeline.
WHIP and WHEP
With this view of the world, WHIP and WHEP can be used both for calling applications, but also as an alternative way to ingest or play back live streams, with lower latency and a near-ubiquitous real-time communication API.
We know GStreamer already provides developers two ways to work with WebRTC streams:
webrtcbin: provides a low-level API, akin to the PeerConnection API that browser-based users of WebRTC will be familiar with
webrtcsrc and webrtcsink: provide high-level elements that can respectively produce/consume media from/to a WebRTC endpoint
At Asymptotic, my colleagues Tarun and Sanchayan have been using these building blocks to implement GStreamer elements for both the WHIP and WHEP specifications. You can find these in the GStreamer Rust plugins repository.
Our initial implementations were based on webrtcbin, but have since been moved over to the higher-level APIs to reuse common functionality (such as automatic encoding/decoding and congestion control). Tarun covered our work in a talk at last year’s GStreamer Conference.
Today, we have 4 elements implementing WHIP and WHEP.
Clients
whipclientsink: This is a webrtcsink-based implementation of a WHIP client, using which you can send media to a WHIP server. For example, streaming your camera to a WHIP server is as simple as:
whepclientsrc: This is work in progress and allows us to build player applications to connect to a WHEP server and consume media from it. The goal is to make playing a WHEP stream as simple as:
The client elements fit quite neatly into how we might imagine GStreamer-based clients could work. You could stream arbitrary stored or live media to a WHIP server, and play back any media a WHEP server provides. Both pipelines implicitly benefit from GStreamer’s ability to use hardware-acceleration capabilities of the platform they are running on.
GStreamer WHIP/WHEP clients
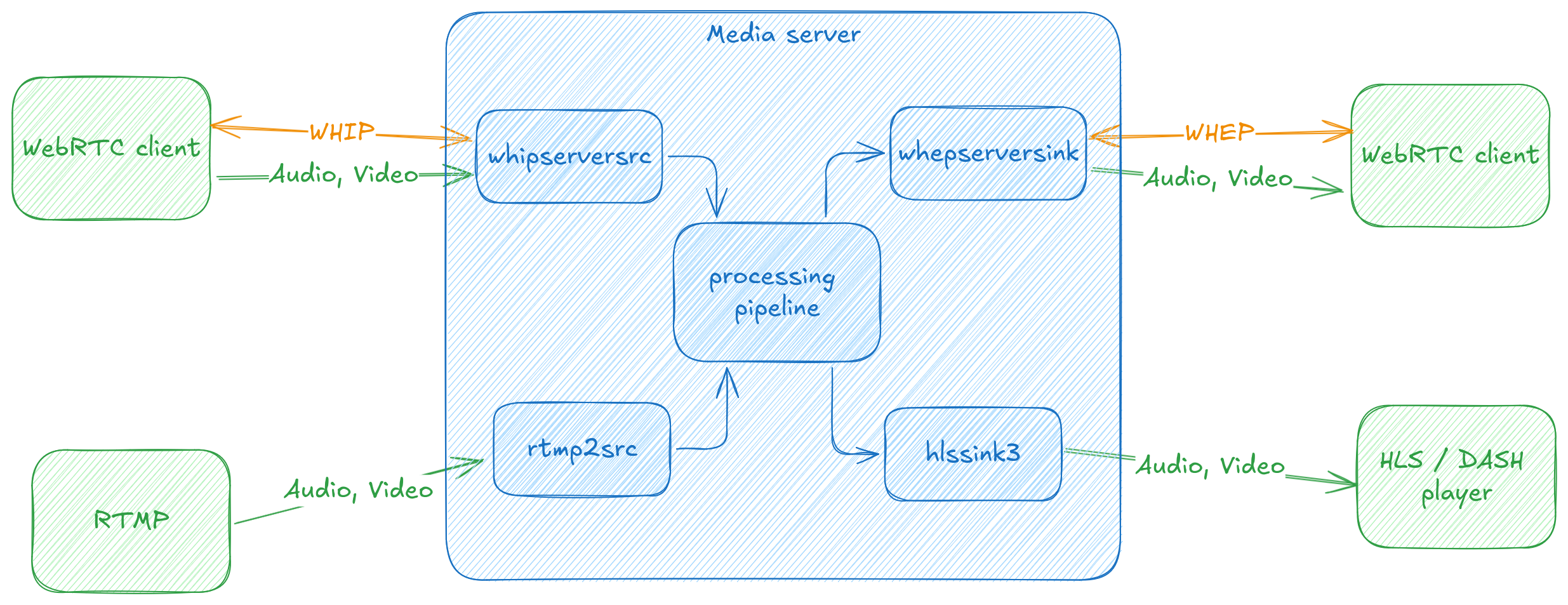
Servers
whipserversrc: Allows us to create a WHIP server to which clients can connect and provide media, each of which will be exposed as GStreamer pads that can be arbitrarily routed and combined as required. We have an example server that can
play all the streams being sent to it.
whepserversink: Finally we have ongoing work to publish arbitrary streams over WHEP for web-based clients to consume this media.
The two server elements open up a number of interesting possibilities. We can ingest arbitrary media with WHIP, and then decode and process, or forward it, depending on what the application requires. We expect that the server API will grow over time, based on the different kinds of use-cases we wish to support.
GStreamer WHIP/WHEP server
This is all pretty exciting, as we have all the pieces to create flexible pipelines for routing media between WebRTC-based endpoints without having to worry about service-specific signalling.
If you’re looking for help realising WHIP/WHEP based endpoints, or other media streaming pipelines, don’t hesitate to reach out to us!
Good evening. Tonight, notes on things I have learned recently while hacking on the Whippet GC
library.
service update
For some time now, the name Whippet has referred to three things.
Firstly, it is the project as a
whole, consisting of an include-only
garbage collection library containing a compile-time configurable choice of specific collector implementations. Also, it is the name of
a specific Immix-derived
collector.
Finally, it is the name of a specific space within that collector, in
which objects are mostly marked in place but can be evacuated if
appropriate.
Well, naming being one of the two hard problems of computer science, I
can only ask for forgiveness and understanding. I have started fixing
this situation with the third component, renaming the whippet space to
the nofl space. Nofl stands for no-free-list, indicating that it’s a
(mostly) mark space but which does bump-pointer allocation instead of using freelists. Also, it
stands for novel, in the sense that as far as I can tell, it is a
design that hasn’t been tried yet.
unreliable evacuation
Following Immix, the
nofl space has always had optimistic evacuation. It prefers to mark
objects in place, but if fragmentation gets too high, it will try to
defragment by evacuating sparse blocks into a small set of empty blocks
reserved for this purpose. If the evacuation reserve fills up, nofl
will dynamically switch to marking in place.
My previous implementation was a bit daft: some subset of blocks would
get marked as being evacuation targets, and evacuation would allocate
into those blocks in ascending address order. Parallel GC threads would
share a single global atomically-updated evacuation allocation pointer.
As you can imagine, this was a serialization bottleneck; I initially
thought it wouldn’t be so important but for some workloads it is.
I had chosen this strategy to maximize utilization of the evacuation
reserve; if you had 8 GC workers, each allocating into their own block,
their blocks won’t all be full at the end of GC; that would waste space.
But
reliability
turns out to be unimportant. It’s more important to let parallel GC
threads do their thing without synchronization, to the extent possible.
Also, this serialized allocation discipline imposed some complexity on
the nofl space implementation; the evacuation allocator was not like the
“normal” allocator. With worker-local allocation buffers, these two
allocators are now essentially the same. (They differ in that the
normal allocator interleaves lazy sweeping with allocation, and can
allocate into blocks with survivors from the last GC instead of
requiring empty blocks.)
eager sweeping
Another initial bad idea I had was to lean too much on lazy sweeping as
a design principle. The idea was that deferring sweeping work until
just before an allocator would write to a block would minimize cache
overhead (you page in a block right when you will use it) and provide
for workload-appropriate levels of parallelism (multiple mutator threads
naturally parallelize sweeping).
Lazy sweeping was very annoying when it came to discovery of empty
blocks. Empty blocks are precious: they can be returned to the OS if
needed, they are useful for evacuation, and they have nice allocation
properties, in that you can just do bump-pointer from beginning to end.
Nofl was discovering empty blocks just in time, from the allocator. If
the allocator acquired a new block and found that it was empty, it would
return it to a special list of empty blocks. Only if all sweepable
pages were exhausted would an allocator use an empty block. But to
prevent an allocator from pausing forever, there was a limit to the
number of empty swept blocks that would be returned to the collector (10, as it
happens); an 11th empty swept block would be given to a mutator for
allocation. And so on and so on. Complicated, and you only know the
number of empty blocks yielded by the last collection when the whole
next allocation cycle has finished.
The obvious solution is some kind of separate mark on blocks, in
addition to a mark on objects. I didn’t do it initially out of fear of
overhead; marking is a fast path. The implementation I ended up making
was a packed bitvector, with one bit per 64 kB block, at the beginning
of each 4 MB slab of blocks. The beginning blocks are for metadata like
this. For reasons, I don’t have the space for full bytes. When marking
an object, if I see that a block’s mark is unset, I do an
atomic_fetch_or_explicit on the byte with memory_order_relaxed
ordering. In this way I only do the atomic op very rarely. It seems
that on ARMv8.1 there is actually an instruction to do atomic bit
setting; everywhere else it’s a
garbage compare-and-swap thing, but on my x64 machine it’s fine.
Then after collection, during the pause, if I see a block is unmarked, I
move it directly to the empty set instead of sweeping it. (I could
probably do this concurrently outside the pause, but that would be for
another day.)
And the overhead? Negative! Negative, in the sense that because I
don’t have to sweep empty blocks, and that (for some workloads)
collection can produce a significant-enough fraction of empty blocks, I
actually see speedups with this strategy, relative to lazy sweeping. It
also simplifies the allocator (no need for that return-the-11th-block
logic).
The only wrinkle is as regards generational collection: nofl currently
uses the sticky mark bit
algorithm,
which has to be applied also to block marks. Subtle, but not
complicated.
fin
Next up is growing and shrinking the nofl-using Whippet collector (which
might need another name), using the membalancer
algorithm,
and then I think I will be ready to move on to getting Whippet into
Guile. Until then, happy hacking!
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and it should be safe
to update from 1.24.x.
Highlighted bugfixes:
Fix APE and Musepack audio file and GIF playback with FFmpeg 7.0
playbin3: Fix potential deadlock with multiple playbin3s with glimagesink used in parallel
qt6: various qmlgl6src and qmlgl6sink fixes and improvements
rtspsrc: expose property to force usage of non-compliant setup URLs for RTSP servers where the automatic fallback doesn't work
urisourcebin: gapless playback and program switching fixes
v4l2: various fixes
va: Fix potential deadlock with multiple va elements used in parallel
meson: option to disable gst-full for static-library build configurations that do not need this
cerbero: libvpx updated to 1.14.1; map 2022Server to Windows11; disable rust variant on Linux if binutils is too old
Various bug fixes, memory leak fixes, and other stability and reliability improvements
Good evening. Tonight, a brief position statement: it is a mistake for
JavaScript’s WeakMap to not be iterable, and we should fix it.
story time
A WeakMap associates a key with a value, as long as the key is
otherwise reachable in a program. (It is an ephemeron
table.)
When WeakMap was added to JavaScript, back in the ES6 times, some
implementors thought that it could be reasonable to implement weak maps
not as a data structure in its own right, but rather as a kind of
property on each object. Under the hood, adding an key→value
association to a map M would set key[M] = value. GC would be free
to notice dead maps and remove their associations in live objects.
If you implement weak maps like this, or are open to the idea of such an
implementation, then you can’t rely on the associations being enumerable
from the map itself, as they are instead spread out among all the key
objects. So, ES6 specified WeakMap as not being
iterable;
given a map, you can’t know what’s in it.
As with many things GC-related, non-iterability of weak maps then gained
a kind of legendary status: the lore states that
non-iterability preserves some key flexibility for JS implementations,
and therefore it is good, and you just have to accept it and move on.
dynamics
Time passed, and two things happened.
One was that this distributed WeakMap implementation strategy did not
pan out; everyone ended up implementing weak maps as their own kind of
object, and people use an algorithm like the one Steve Fink described a
couple years
ago
to compute the map×key⇒value conjunction. The main original
motivation for non-iterability was no longer valid.
(Full disclosure: I did work on ES6 and had a hand in
FinalizationRegistry but don’t do JS language work currently.)
Thing is, your iterable WeakMap is strictly inferior to what the
browser can provide: its implementation is extraordinarily gnarly,
shipped over the wire instead of already in the browser, uses more
memory, is single-threaded and high-latency (because
FinalizationRegistry), and non-standard. What if instead as language
engineers we just did our jobs and standardized iterability, as we do
with literally every other collection in the JS standard?
Just this morning I wrote yet another iterable
WeakSet
(which has all the same concerns as WeakMap), and while it’s
sufficient for my needs, it’s not good (lacking prompt cleanup of dead
entries), and by construction can’t be great (because it has to be
redundantly implemented on top of WeakSet instead of being there
already).
I am sympathetic to deferring language specification decisions to allow
the implementation space to be explored, but when the exploration is
done and the dust has settled, we shouldn’t hesitate to pick a winner:
JS weak maps and sets should be iterable. Godspeed, brave TC39 souls;
should you take up this mantle, you are doing the Lord’s work!
Thanks to Philip Chimento for notes on the timeline and Joyee Cheung for notes on the iterable WeakMap implementation in the WeakRef spec. All errors
mine, of course!
All programmers use the modulo operator, but virtually none have stopped to consider what it actually is, and that's why one of the most powerful features of it doesn't work in most programming languages.
This article touches abstract mathematics in order to explain why.
The GStreamer Conference 2024 GStreamer Conference will take place
on Monday-Tuesday 7-8 October 2024 in Montréal, Québec, Canada.
It is a conference for developers, community members, decision-makers,
industry partners, researchers, students and anyone else interested
in the GStreamer multimedia framework or Open Source and cross-platform
multimedia.
There will also be a hackfest just after the conference.
The call for presentations is now open for talk proposals and lightning talks.
Please submit your talk now!
Talks can be on almost anything multimedia related, ranging from talks about
applications to challenges in the lower levels in the stack or hardware.
We want to hear from you, what you are working on, what you are using
GStreamer for, what difficulties you have encountered and how you solved them,
what your plans are, what you like, what you dislike, how to improve things!
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.24.x.
Highlighted bugfixes:
Fix compatibility with FFmpeg 7.0
qmlglsink: Fix failure to display content on recent Android devices
adaptivedemux: Fix handling of closed caption streams
cuda: Fix runtime compiler loading with old CUDA tookit
decodebin3 stream selection handling fixes
d3d11compositor, d3d12compositor: Fix transparent background mode with YUV output
d3d12converter: Make gamma remap work as intended
h264decoder: Update output frame duration for interlaced video when second field frame is discarded
macOS audio device provider now listens to audio devices being added/removed at runtime
Rust plugins: audioloudnorm, s3hlssink, gtk4paintablesink, livesync and webrtcsink fixes
videoaggregator: preserve features in non-alpha caps for subclasses with non-system memory sink caps
vtenc: Fix redistribute latency spam
v4l2: fixes for complex video formats
va: Fix strides when importing DMABUFs, dmabuf handle leaks, and blocklist unmaintained Intel i965 driver for encoding
waylandsink: Fix surface cropping for rotated streams
webrtcdsp: Enable multi_channel processing to fix handling of stereo streams
Various bug fixes, memory leak fixes, and other stability and reliability improvements
The pitch is that if you use Whippet, you get a low-fuss small
dependency to vendor into your source
tree
that offers you access to a choice of advanced garbage collectors: not
just the conservative mark-sweep collector from BDW-GC, but also copying
collectors, an Immix-derived collector, generational collectors, and so
on. You can choose the GC that fits your problem domain, like Java
people have done for many
years.
The Whippet API is designed to be a no-overhead
abstraction
that decouples your language run-time from the specific choice of GC.
I co-maintain Guile and will be working on integrating Whippet in the
next months, and have high hopes for success.
I’m delighted to share that Whippet was granted financial support from
the European Union via the NGI zero core fund,
administered by the Dutch non-profit, NLnet
foundation. See the NLnet project
page for the overview.
This funding allows me to devote time to Whippet to bring it from
proof-of-concept to production. I’ll finish the missing
features,
spend some time adding tracing support, measuring performance, and
sanding off any rough edges, then work on integrating Whippet into
Guile.
This bloggery is a first update of the progress of the funded NLnet
project.
a new collector!
I landed a new collector a couple weeks ago, a parallel copying
collector (PCC).
It’s like a semi-space
collector,
in that it always evacuates objects (except large
objects,
which are managed in their own space). However instead of having a
single global bump-pointer allocation region, it breaks the heap into
64-kB blocks. In this way it supports multiple mutator threads:
mutators do local bump-pointer allocation into their own block, and when
their block is full, they fetch another from the global store.
The block size is 64 kB, but really it’s 128 kB, because each block has
two halves: the active region and the copy reserve. It’s a copying
collector, after all. Dividing each block in two allows me to easily
grow and shrink the heap while ensuring there is always enough reserve
space.
Blocks are allocated in 64-MB aligned slabs, so you get 512 blocks in a
slab. The first block in a slab is used by the collector itself, to
keep metadata for the rest of the blocks, for example a chain pointer
allowing blocks to be collected in lists, a saved allocation pointer for
partially-filled blocks, whether the block is paged in or out, and so
on.
The PCC not only supports parallel mutators, it can also trace in
parallel. This mechanism works somewhat like allocation, in which
multiple trace workers compete to evacuate objects into their local
allocation buffers; when an allocation buffer is full, the trace
worker grabs another, just like mutators do.
However, unlike the simple semi-space collector which uses a Cheney grey
worklist, the PCC uses the fine-grained work-stealing parallel
tracer
originally developed for Whippet’s Immix-like collector. Each trace
worker maintains a local queue of objects that need
tracing,
which currently has 1024 entries. If the local queue becomes full, the
worker will publish 3/4 of those entries to the worker’s shared
worklist.
When a worker runs out of local work, it will first try to remove work
from its own shared worklist, then will try to steal from other workers.
Of course, because threads compete to evacuate objects, we have to use
atomic compare-and-swap instead of simple forwarding pointer
updates;
if you only have one mutator thread and are OK with just one tracing
thread, you can avoid the ~30% performance penalty that atomic
operations impose. The PCC generally starts to win over a semi-space
collector when it can trace with 2 threads, and gets better with each
thread you add.
I sometimes wonder whether the worklist should contain grey edges or
grey objects. MMTk seems to do the former, and bundles edges into work
packets, which are the unit of work sharing. I don’t know yet what is
best and look forward to experimenting once I have better benchmarks.
Anyway, maintaining an external worklist is cheating in a way: unlike
the Cheney worklist, this memory is not accounted for as part of the
heap size. If you are targetting a microcontroller or something,
probably you need to choose a different kind of collector. Fortunately,
Whippet enables this kind of choice, as it contains a number of
collector implementations.
What about benchmarks? Well, I’ll be doing those soon in a more
rigorous way. For now I will just say that it seems to behave as
expected and I am satisfied; it is useful to have a performance oracle
against which to compare other collectors.
In the future I should do some more work to make finalizers support
generations, if the collector is generational, allowing a minor
collection to avoid visiting finalizers for old objects. But this is a
straightforward extension that will happen at some point.
future!
And that’s the end of this update. Next up, I am finally going to
tackle heap resizing, using the membalancer
approach.
Then basic Windows and Mac support, then I move on to the tracing and
performance measurement phase. Onwards and upwards!
It would be a shame if guardians were primitive, as they are a
relatively niche language feature. Guile has them, yes, but really what
Guile has is bugs: because Guile implements guardians on top of
BDW-GC’s
finalizers
(without topological ordering), all the other things that finalizers
might do in Guile (e.g. closing file ports) might run at the same time
as the objects protected by guardians. For the specific object being
guarded, this isn’t so much of a problem, because when you put an object
in the guardian, it arranges to prepend the guardian finalizer before
any existing finalizer. But when a whole clique of objects becomes
unreachable, objects referred to by the guarded object may be finalized.
So the object you get back from the guardian might refer to, say,
already-closed file ports.
The guardians-are-primitive solution is to add a special guardian pass
to the collector that will identify unreachable guarded objects. In
this way, the transitive closure of all guarded objects will be already visited by
the time finalizables are computed, protecting them from finalization. This would be sufficient, but is it necessary?
answers?
Thinking more abstractly, perhaps we can solve this issue and others
with a set of finalizer priorities: a collector could have, say, 10
finalizer priorities, and run the finalizer
fixpoint
once per priority, in order. If no finalizer is registered at a given
priority, there is no overhead. A given embedder (Guile, say) could use
priority 0 for guardians, priority 1 for “normal” finalizers, and ignore
the other priorities. I think such a facility could also support other
constructs, including Java’s phantom references, weak references, and
reference queues, especially when combined with ephemerons.
Anyway, all this is a note for posterity. Are there other interesting
mutator-exposed GC constructs that can’t be implemented with a
combination of ephemerons and multi-priority finalizers? Do let me
know!
The GStreamer team is pleased to announce another release of liborc,
the Optimized Inner Loop Runtime Compiler, which is used for SIMD acceleration
in GStreamer plugins such as audioconvert, audiomixer, compositor, videoscale,
and videoconvert, to name just a few.
This is a minor bug-fix release, and also includes a security fix.
Highlights:
Security: Fix error message printing buffer overflow leading to possible code execution in orcc with specific input files (CVE-2024-40897). This only affects developers and CI environments using orcc, not users of liborc.
div255w: fix off-by-one error in the implementations
x86: only run AVX detection if xgetbv is available
x86: fix AVX detection by implementing the check recommended by Intel
Only enable JIT compilation on Apple arm64 if running on macOS, fixes crashes on iOS
Fix potential crash in emulation mode if logging is enabled
Handle undefined TARGET_OS_OSX correctly
orconce: Fix typo in GCC __sync-based implementation
orconce: Fix usage of __STDC_NO_ATOMICS__
Fix build with MSVC 17.10 + C11
Support stack unwinding on Windows
Major opcode and instruction set code clean-ups and refactoring
Refactor allocation and chunk initialization of code regions
Fall back to emulation on Linux if JIT support is not available, e.g. because of SELinux sandboxing or noexec mounting)
As usual this release follows the latest gtk-rs 0.20 release and the corresponding API changes.
This release features relatively few changes and mostly contains the
addition of some convenience APIs, the addition of bindings for some minor
APIs, addition of bindings for new GStreamer 1.26 APIs, and various optimizations.
The new release also brings a lot of bugfixes, most of which were
already part of the bugfix releases of the previous release series.
Details can be found in the release notes for gstreamer-rs.
The code and documentation for the bindings is available on the freedesktop.org GitLab
The new 0.13 version of the GStreamer Rust plugins features many
improvements to the existing plugins as well as various new plugins. A
majority of the changes were already backported to the 0.12 release series
and its bugfix releases, which is part of the GStreamer 1.24 binaries.
A full list of available plugins can be seen in the repository's README.md.
Details for this release can be found in the release notes for gst-plugins-rs.
If you find any bugs, notice any missing features or other issues please
report them in GitLab for the bindings
or the plugins.
I am pleased to announce the release of scikit-survival 0.23.0.
This release adds support for scikit-learn 1.4 and 1.5, which includes missing value support for RandomSurvivalForest.
For more details on missing values support, see the section
in the release announcement for 0.23.0.
Moreover, this release fixes critical bugs. When fitting SurvivalTree, the sample_weight is now correctly considered when computing the log-rank statistic for each split. This change also affects RandomSurvivalForest and ExtraSurvivalTrees which pass sample_weight to the individual trees in the ensemble. Therefore, the outputs produced by SurvivalTree,
RandomSurvivalForest, and ExtraSurvivalTrees will differ from previous releases.
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.24.x.
Highlighted bugfixes:
webrtcsink: Support for AV1 via nvav1enc, av1enc or rav1enc encoders
AV1 RTP payloader/depayloader fixes to work correctly with Chrome and Pion WebRTC
There are times when you feel your making no progress and there are other times when things feel like they are landing in quick succession. Luckily this definitely is the second when a lot of our long term efforts are finally coming over the finish line. As many of you probably know our priorities tend to be driven by a combination of what our RHEL Workstation customers need, what our hardware partners are doing and what is needed for Fedora Workstation to succeed. We also try to be good upstream partners and do patch reviews and participate where we can in working on upstream standards, especially those of course of concern to our RHEL Workstation and Server users. So when all those things align we are at our most productive and that seems to be what is happening now. Everything below is features in flight that will at the latest land in Fedora Workstation 41.
Artificial Intelligence
IBM Granite LLM models usher in a new era of open source AI.
One of the areas of great importance to Red Hat currently is working on enabling our customers and users to take advantage of the advances in Artificial Intelligence. We do this in a lot of interesting ways like our recently announced work with IBM to release the high quality Granite AI models under terms that make them the most open major vendor AI models according to the Stanford Foundation Model Transparency Index , but not only are we releasing the full LLM source code, we are also creating a project to make modifying and teaching the LLM a lot easier through a project we call Instructlab. Instructlab is enabling almost anyone to quickly download a Granite LLM model and start teaching it specific things relevant to you or your organization. This put you in control of the AI and what it knows and can do as opposed to being demoted to a pure consumer.
And it is not just Granite, we are ensuring other other major AI projects will work with Fedora too, like Meta’s popular Llama LLM. And a big step for that is how Tom Rix has been working on bringing in AMD accelerated support (ROCm) for PyTorch to Fedora. PyTorch is an optimized tensor library for deep learning using GPUs and CPUs. The long term goal is that you should be able to just install PyTorch on Fedora and have it work hardware accelerated with any of the 3 major GPU vendors chipsets.
NVIDIA in Fedora
So the clear market leader at the moment for powering AI workloads in NVIDIA so I am also happy to let you know about two updates we are working on that will make you life better on Fedora when using NVIDIA GPUs, be that for graphics or for compute or Artificial Intelligence. So for the longest time we have had easy install of the NVIDIA driver through GNOME Software in Fedora Workstation, unfortunately this setup never dealt with what is now the default usecase, which is using it with a system that has secure boot enabled. So the driver install was dropped from GNOME Software in our most recent release as the only way for people to get it working was through using mokutils on the command line, but the UI didn’t tell you that. Well we of course realize that sending people back to the command line to get this driver installed is highly unfortunate so Milan Crha has been working together with Alan Day and Jakub Steiner to come up with a streamlined user experience in GNOME Software to let you install the binary NVIDIA driver and provide you with an integrated graphical user interface help to sign the kernel module for use with secure boot. This is a bit different than what we for instance are doing in RHEL, where we are working with NVIDIA to provide pre-signed kernel modules, but that is a lot harder to do in Fedora due to the rapidly updating kernel versions and which most Fedora users appreciate as a big plus. So instead what we are for opting in Fedora is as I said to make it simple for you to self-sign the kernel module for use with secure boot. We are currently looking at when we can make this feature available, but no later than Fedora Workstation 41 for sure.
Toolbx getting top notch NVIDIA integration
Container Toolbx enables developers quick and easy access to their favorite development platforms
Toolbx, our incredible developer focused containers tool, is going from strength to strength these days with the rewrite from the old shell scripts to Go starting to pay dividends. The next major feature that we are closing in on is full NVIDIA driver support with Toolbx. As most of you know Toolbx is our developer container solution which makes it super simple to set up development containers with specific versions of Fedora or RHEL or many other distributions. Debarshi Ray has been working on implementing support for the official NVIDIA container device interface module which should enable us to provide full NVIDIA and CUDA support for Toolbx containers. This should provide reliable NVIDIA driver support going forward and Debarshi is currently testing various AI related container images to ensure they run smoothly on the new setup.
We are also hoping the packaging fixes to subscription manager will land soon as that will make using RHEL containers on Fedora a lot smoother. While this feature basically already works as outlined here we do hope to make it even more streamlined going forward.
Open Source NVIDIA support
Of course being Red Hat we haven’t forgotten about open source here, you probably heard about Nova our new Rust based upstream kernel driver for NVIDIA hardware which will provided optimized support for the hardware supported by NVIDIAs firmware (basically all newer ones) and accelerate Vulkan through the NVK module and provide OpenGL through Zink. That effort is still quite early days, but there is some really cool developments happening around Nova that I am not at liberty to share yet, but I hope to be able to talk about those soon.
High Dynamic Range (HDR)
Jonas Ådahl after completing the remote access work for GNOME under Wayland has moved his focus to help land the HDR support in mutter and GNOME Shell. He recently finished rebasing his HDR patches onto a wip merge request from
Georges Stavracas which ported gnome-shell to using paint nodes,
So the HDR enablement in mutter and GNOME shell is now a set of 3 patches.
With this the work is mostly done, what is left is avoiding over exposure of the cursor, and inhibiting direct scanout.
We also hope to help finalize the upstream Wayland specs soon so that everyone can implement this and know the protocols are stable and final.
DRM leasing – VR Headsets
The most common usecase for DRM leasing is VR headsets, but it is also a useful feature for things like video walls. José Expósito is working on finalizing a patch for it using the Wayland protocol adopted by KDE and others. We where somewhat hesitant to go down this route as we felt a portal would have been a better approach, especially as a lot of our experienced X.org developers are worried that Wayland is in the process of replicating one of the core issues with X through the unmanageable plethora of Wayland protocols that is being pushed. That said, the DRM leasing stuff was not a hill worth dying on here, getting this feature out to our users in a way they could quickly use was more critical, so DRM leasing will land soon through this merge request.
Explicit sync
Another effort that we have put a lot of effort into together with our colleagues at NVIDIA is landing support for what is called explicit sync into the Linux kernel and the graphics drivers.The linux graphics stack was up to this point using something called implicit sync, but the NVIDIA drivers did not work well with that and thus people where experiencing ‘blinking’ applications under Wayland. So we worked with NVIDIA and have landed the basic support in the kernel and in GNOME and thus once the 555 release of the NVIDIA driver is out we hope the ‘blinking’ issues are fully resolved for your display. There has been some online discussion about potential performance gains from this change too, across all graphics drivers, but the reality of this is somewhat uncertain or at least it is still unclear if there will be real world measurable gains from adding explicit sync. I heard knowledgeable people argue both sides with some saying there should be visible performance gains while others say the potential gains will be so specific that unless you write a test to benchmark it explicitly you will not be able to detect a difference. But what is beyond doubt is that this will make using the NVIDIA stack with Wayland a lot better a that is a worthwhile goal in itself. The one item we are still working on is integrating the PipeWire support for explicit sync into our stack, because without it you might have the same flickering issues with PipeWire streams on top of the NVIDIA driver that you have up to now seen on your screen. So for instance if you are using PipeWire for screen capture it might look fine on screen with the fixes already merged, but the captured video has flickering. Wim Taymans landed some initial support in PipeWire already so now Michel Dänzer is working on implementing the needed bits for PipeWire in mutter. At the same time Wim is working on ensuring we have a testing client available to verify the compositor support. Once everything has landed in mutter and we been able to verify that it works with the sample client we will need to add support to client applications interacting with PipeWire, like Firefox, Chrome, OBS Studio and GNOME-remote-desktop.
Two weeks ago the GStreamer Spring Hackfest took place in Thessaloniki,
Greece. I had a great time. I hacked a bit on VA, Vulkan and my toy,
planet-rs, but mostly I ate
delicious Greek food ☻. A big thanks to our hosts: Vivia, Jordan and Sebastian!
And now, writing this supposed small note, I recalled that I have in my to-do
list an item to write a comment about
GstVulkanOperation,
an addition to GstVulkan
API which helps
with the synchronization of operations on frames, in order to enable Vulkan
Video.
Originally, GstVulkan API didn’t provide almost any synchronization operation,
beside
fences, and
that appeared to be enough for elements, since they do simple Vulkan
operations. Nonetheless, as soon as we enabled
VK_VALIDATION_FEATURE_ENABLE_SYNCHRONIZATION_VALIDATION_EXT feature, which
reports resource access conflicts due to missing or incorrect synchronization
operations between action
[*],
a sea of hazard operation warnings drowned us
[*].
Hazard operations are a sequence of read/write commands in a memory area, such
as an image, that might be re-ordered, or racy even.
Why are those hazard operations reported by the Vulkan Validation Layer, if
the programmer pushes the commands to execute in queue in order? Why is explicit
synchronization required? Because, as the great blog post from Hans-Kristian
Arntzen, Yet another blog explaining Vulkan
synchronization,
(make sure you read it!) states:
[…] all commands in a queue execute out of order. Reordering may happen across
command buffers and even vkQueueSubmits
In order to explain how synchronization is done in Vulkan, allow me to yank a
couple definitions stated by the specification:
Commands are instructions that are recorded in a device’s queue. There are
four types of commands: action, state, synchronization and indirection.
Synchronization commands impose ordering constraints on action commands, by
introducing explicit execution and memory dependencies.
Operation is an arbitrary amount of commands recorded in a device’s queue.
Since the driver can reorder commands (perhaps for better performance, dunno),
we need to send explicit synchronization commands to the device’s queue to
enforce a specific sequence of action commands.
Nevertheless, Vulkan doesn’t offer fine-grained dependencies between individual
operations. Instead, dependencies are expressed as a relation of two elements,
where each element is composed by the intersection of scope and operation. A
scope is a concept in the specification that, in practical terms, can be
either pipeline stage (for execution dependencies), or both pipeline stage
and memory access type (for memory dependencies).
First let’s review execution dependencies through pipeline stages:
Every command submitted to a device’s queue goes through a sequence of steps
known as pipeline stages. This sequence of
steps
is one of the very few implicit ordering guarantees that Vulkan has. Draw calls,
copy commands, compute dispatches, all go through certain sequential stages,
which amount of stages to cover depends on the specific command and the current
command buffer state.
In order to visualize an abstract execution dependency let’s imagine two compute
operations and the first must happen before the second.
Operation 1 Sync command Operation 2
The programmer has to specify the Sync command in terms of two scopes
(Scope 1 and Scope 2), in this execution dependency case, two pipeline
stages.
The driver generates an intersection between commands in Operation 1 and
Scope 1 defined as Scoped operation 1. The intersection contains all the
commands in Operation 1 that go through up to the pipeline stage defined in
Scope 1. The same is done with Operation 2 and Scope 2 generating
Scoped operation 2.
Finally, we got an execution dependency that guarantees that Scoped operation 1 happens before Scoped operation 2.
Now let’s talk about memory dependencies:
First we need to understand the concepts of memory availability and
visibility. Their formal
definition
in Vulkan are a bit hard to grasp since they come from the Vulkan memory model,
which is intended to abstract all the ways of how hardware access memory.
Perhaps we could say that availability is the operation that assures the
existence of the required memory; while visibility is the operation that
assures it’s possible to read/write the data in that memory area.
Memory dependencies are limited the Operation 1 that be done before memory
availability and Operation 2 that have to be done after its visibility.
But again, there’s no fine-grained way to declare that memory dependency.
Instead, there are memory access
types,
which are functions used by descriptor types, or functions for pipeline stage to
access memory, and they are used as access scopes.
All in all, if a synchronization command defining a memory dependency between
two operations, it’s composed by the intersection of between each command and a
pipeline stage, intersected with the memory access type associated with the
memory processed by those commands.
Now that the concepts are more or less explained we could see those concepts
expressed in code. The synchronization command for execution and memory
dependencies is defined by
VkDependencyInfoKHR.
And it contains a set of barrier arrays, for memory, buffers and
images. Barriers express the relation of dependency between two operations. For
example, Image barriers use
VkImageMemoryBarrier2
which contain the mask for source pipeline stage (to define Scoped operation 1), and the mask for the destination pipeline stage (to define Scoped operation 2); the mask for source memory access type and the mask for the
destination memory access to define access scopes; and also layout
transformation declaration.
First draw samples a texture in the fragment shader. Second draw writes to
that texture as a color attachment.
This is a Write-After-Read (WAR) hazard, which you would usually only need an
execution dependency for - meaning you wouldn’t need to supply any memory
barriers. In this case you still need a memory barrier to do a layout
transition though, but you don’t need any access types in the src access mask.
The layout transition itself is considered a write operation though, so you do
need the destination access mask to be correct - or there would be a
Write-After-Write (WAW) hazard between the layout transition and the color
attachment write.
Other explicit synchronization mechanisms, along with barriers, are semaphores
and fences. Semaphores are a synchronization primitive that can be used to
insert a dependency between operations without notifying the host; while
fences are a synchronization primitive that can be used to insert a dependency
from a queue to the host. Semaphores and fences are expressed in the
VkSubmitInfo2KHR structure.
As a preliminary conclusion, synchronization in Vulkan is hard and a helper API
would be very helpful. Inspired by FFmpeg work done by
Lynne, I added GstVulkanOperation object helper to
GStreamer Vulkan API.
GstVulkanOperation object helper aims to represent an operation in the sense
of the Vulkan specification mentioned before. It owns a command buffer as public
member where external commands can be pushed to the associated device’s queue.
gst_vulkan_operation_end
wraps both vkEndCommandBuffer and either vkQueueSubmit or
vkQueueSubmit2 (the object internally handle both depending on the driver
support).
Internally, GstVulkanOperation contains two arrays:
The array of dependency frames, which are the set of frames, each
representing an operation, which will hold dependency relationships with
other dependency frames.
When calling gst_vulkan_operation_end the frame’s barrier state for each
frame in the array is updated.
Also, each dependency frame creates a timeline
semaphore,
which will be signaled when a command, associated with the frame, is executed
in the device’s queue.
The array of barriers, which contains a list of synchronization commands.
gst_vulkan_operation_add_frame_barrier
fills and appends a VkImageMemoryBarrier2KHR associated with a frame, which
can be in the array of dependency frames.
/* assume a engine where out frames can be used for DPB frames, */ /* so a barrier for layout transition is required */ gst_vulkan_operation_add_frame_barrier(exec, out, VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT, VK_ACCESS_2_VIDEO_DECODE_WRITE_BIT_KHR, VK_IMAGE_LAYOUT_VIDEO_DECODE_DPB_KHR,NULL);
Here, just one memory barrier is required for memory layout
transition,
but semaphores are required to signal when an output frame and its DPB frames
are processed, and later, the output frame can be used as a DPB frame.
Otherwise, the output frame might not be fully reconstructed with it’s used as
DPB for the next output frame, generating only noise.
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.24.x.
Highlighted bugfixes:
audioconvert: support more than 64 audio channels
avvidec: fix dropped frames when doing multi-threaded decoding of I-frame codecs such as DV Video
mpegtsmux: Correctly time out in live pipelines, esp. for sparse streams like KLV and DVB subtitles
vtdec deadlock fixes on shutdown and format/resolution changes (as might happen with e.g. HLS/DASH)
fmp4mux, isomp4mux: Add support for adding AV1 header OBUs into the MP4 headers, and add language from tags
gtk4paintablesink improvements: fullscreen mode and gst-play-1.0 support
webrtcsink: add support for insecure TLS and improve error handling and VP9 handling
vah264enc, vah265enc: timestamp handling fixes; generate IDR frames on force-keyunit-requests, not I frames
v4l2codecs: decoder: Reorder caps to prefer `DMA_DRM` ones, fixes issues with playbin3
Visualizer plugins fixes
Avoid using private APIs on iOS
various bug fixes, memory leak fixes, and other stability and reliability improvements
Last weeks were a bit hectic. First, with a couple friends we biked the
southwest of the Netherlands for almost a week. The next week, the last one, I
attended the 2024 Display Next
Hackfest
The GStreamer project is thrilled to announce that this year's GStreamer
Conference will take place on Monday-Tuesday 7-8 October 2024
in Montréal, Québec, Canada, followed by a hackfest.
Talk slots will be available in varying durations from 20 minutes up to
45 minutes. Whatever you're doing or planning to do with GStreamer,
we'd like to hear from you!
We also plan to have sessions with short lightning talks / demos /
showcase talks for those who just want to show what they've been
working on or do a mini-talk instead of a full-length talk. Lightning
talk slots will be allocated on a first-come-first-serve basis, so make
sure to reserve your slot if you plan on giving a lightning talk.
A GStreamer hackfest will take place right after the conference, on 9-10 October 2024.
During all these years using GStreamer, I’ve been having to deal with GstSegments in many situations. I’ve always have had an intuitive understanding of the meaning of each field, but never had the time to properly write a good reference explanation for myself, ready to be checked at those times when the task at hand stops being so intuitive and nuisances start being important. I used the notes I took during an interesting conversation with Alba and Alicia about those nuisances, during the GStreamer Hackfest in A Coruña, as the seed that evolved into this post.
But what are actually GstSegments? They are the structures that track the values needed to synchronize the playback of a region of interest in a media file.
GstSegments are used to coordinate the translation between Presentation Timestamps (PTS), supplied by the media, and Runtime.
PTS is the timestamp that specifies, in buffer time, when the frame must be displayed on screen. This buffer time concept (called buffer running-time in the docs) refers to the ideal time flow where rate isn’t being had into account.
Decode Timestamp (DTS) is the timestamp that specifies, in buffer time, when the frame must be supplied to the decoder. On decoders supporting P-frames (forward-predicted) and B-frames (bi-directionally predicted), the PTS of the frames reaching the decoder may not be monotonic, but the PTS of the frames reaching the sinks are (the decoder outputs monotonic PTSs).
Runtime (called clock running time in the docs) is the amount of physical time that the pipeline has been playing back. More specifically, the Runtime of a specific frame indicates the physical time that has passed or must pass until that frame is displayed on screen. It starts from zero.
Base time is the point when the Runtime starts with respect to the input timestamp in buffer time (PTS or DTS). It’s the Runtime of the PTS=0.
Start, stop, duration: Those fields are buffer timestamps that specify when the piece of media that is going to be played starts, stops and how long that portion of the media is (the absolute difference between start and stop, and I mean absolute because a segment being played backwards may have a higher start buffer timestamp than what its stop buffer timestamp is).
Position is like the Runtime, but in buffer time. This means that in a video being played back at 2x, Runtime would flow at 1x (it’s physical time after all, and reality goes at 1x pace) and Position would flow at 2x (the video moves twice as fast than physical time).
The Stream Time is the position in the stream. Not exactly the same concept as buffer time. When handling multiple streams, some of them can be offset with respect to each other, not starting to be played from the begining, or even can have loops (eg: repeating the same sound clip from PTS=100 until PTS=200 intefinitely). In this case of repeating, the Stream time would flow from PTS=100 to PTS=200 and then go back again to the start position of the sound clip (PTS=100). There’s a nice graphic in the docs illustrating this, so I won’t repeat it here.
Time is the base of Stream Time. It’s the Stream time of the PTS of the first frame being played. In our previous example of the repeating sound clip, it would be 100.
There are also concepts such as Rate and Applied Rate, but we didn’t get into them during the discussion that motivated this post.
So, for translating between Buffer Time (PTS, DTS) and Runtime, we would apply this formula:
And for translating between Buffer Time (PTS, DTS) and Stream Time, we would apply this other formula:
StreamTime = BufferTime * AppliedRate + Time
And that’s it. I hope these notes in the shape of a post serve me as reference in the future. Again, thanks to Alicia, and especially to Alba, for the valuable clarifications during the discussion we had that day in the Igalia office. This post wouldn’t have been possible without them.
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.24.x.
The GStreamer team is pleased to announce another bug fix release
in the now old-stable 1.22 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.22.x.
It’s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation’s current status and some exciting upcoming changes.
Finances
As you may be aware, the GNOME Foundation has operated at a deficit (nonprofit speak for a loss – ie spending more than we’ve been raising each year) for over three years, essentially running the Foundation on reserves from some substantial donations received 4-5 years ago. The Foundation has a reserves policy which specifies a minimum amount of money we have to keep in our accounts. This is so that if there is a significant interruption to our usual income, we can preserve our core operations while we work on new funding sources. We’ve now “hit the buffers” of this reserves policy, meaning the Board can’t approve any more deficit budgets – to keep spending at the same level we must increase our income.
One of the board’s top priorities in hiring Holly was therefore her experience in communications and fundraising, and building broader and more diverse support for our mission and work. Her goals since joining – as well as building her familiarity with the community and project – have been to set up better financial controls and reporting, develop a strategic plan, and start fundraising. You may have noticed the Foundation being more cautious with spending this year, because Holly prepared a break-even budget for the Board to approve in October, so that we can steady the ship while we prepare and launch our new fundraising initiatives.
Strategy & Fundraising
The biggest prerequisite for fundraising is a clear strategy – we need to explain what we’re doing and why it’s important, and use that to convince people to support our plans. I’m very pleased to report that Holly has been working hard on this and meeting with many stakeholders across the community, and has prepared a detailed and insightful five year strategic plan. The plan defines the areas where the Foundation will prioritise, develop and fund initiatives to support and grow the GNOME project and community. The board has approved a draft version of this plan, and over the coming weeks Holly and the Foundation team will be sharing this plan and running a consultation process to gather feedback input from GNOME foundation and community members.
In parallel, Holly has been working on a fundraising plan to stabilise the Foundation, growing our revenue and ability to deliver on these plans. We will be launching a variety of fundraising activities over the coming months, including a development fund for people to directly support GNOME development, working with professional grant writers and managers to apply for government and private foundation funding opportunities, and building better communications to explain the importance of our work to corporate and individual donors.
Board Development
Another observation that Holly had since joining was that we had, by general nonprofit standards, a very small board of just 7 directors. While we do have some committees which have (very much appreciated!) volunteers from outside the board, our officers are usually appointed from within the board, and many board members end up serving on multiple committees and wearing several hats. It also means the number of perspectives on the board is limited and less representative of the diverse contributors and users that make up the GNOME community.
Holly has been working with the board and the governance committee to reduce how much we ask from individual board members, and improve representation from the community within the Foundation’s governance. Firstly, the board has decided to increase its size from 7 to 9 members, effective from the upcoming elections this May & June, allowing more voices to be heard within the board discussions. After that, we’re going to be working on opening up the board to more participants, creating non-voting officer seats to represent certain regions or interests from across the community, and take part in committees and board meetings. These new non-voting roles are likely to be appointed with some kind of application process, and we’ll share details about these roles and how to be considered for them as we refine our plans over the coming year.
Elections
We’re really excited to develop and share these plans and increase the ways that people can get involved in shaping the Foundation’s strategy and how we raise and spend money to support and grow the GNOME community. This brings me to my final point, which is that we’re in the run up to the annual board elections which take place in the run up to GUADEC. Because of the expansion of the board, and four directors coming to the end of their terms, we’ll be electing 6 seats this election. It’s really important to Holly and the board that we use this opportunity to bring some new voices to the table, leading by example in growing and better representing our community.
Allan wrote in the past about what the board does and what’s expected from directors. As you can see we’re working hard on reducing what we ask from each individual board member by increasing the number of directors, and bringing additional members in to committees and non-voting roles. If you’re interested in seeing more diverse backgrounds and perspectives represented on the board, I would strongly encourage you consider standing for election and reach out to a board member to discuss their experience.
Thanks for reading! Until next time.
Best Wishes, Rob President, GNOME Foundation
Update 2024-04-27: It was suggested in the Discourse thread that I clarify the interaction between the break-even budget and the 1M EUR committed by the STF project. This money is received in the form of a contract for services rather than a grant to the Foundation, and must be spent on the development areas agreed during the planning and application process. It’s included within this year’s budget (October 23 – September 24) and is all expected to be spent during this fiscal year, so it doesn’t have an impact on the Foundation’s reserves position. The Foundation retains a small % fee to support its costs in connection with the project, including the new requirement to have our accounts externally audited at the end of the financial year. We are putting this money towards recruitment of an administrative assistant to improve financial and other operational support for the Foundation and community, including the STF project and future development initiatives.
(also posted to GNOME Discourse, please head there if you have any questions or comments)
In this post I’ll try to document the journey starting from a WebKit issue and
ending up improving third-party projects that WebKitGTK and WPEWebKit depend on.
I’ve been working on WebKit’s GStreamer backends for a while. Usually some new
feature needed on WebKit side would trigger work …
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.24.x.
Highlighted bugfixes:
H.264 parsing regression fixes
WavPack typefinding improvements
Video4linux fixes and improvements
Android build and runtime fixes
macOS OpenGL memory leak and robustness fixes
Qt/QML video sink fixes
Windows MSVC binary packages: fix libvpx avx/avx2/avx512 instruction set detection
Package new analytics and mse libraries in binary packages
various bug fixes, build fixes, memory leak fixes, and other stability and reliability improvements
So Fedora Workstation 40 Beta has just come out so I thought I share a bit about some of the things we are working on for Fedora Workstation currently and also major changes coming in from the community.
Flatpak
Flatpaks has been a key part of our strategy for desktop applications for a while now and we are working on a multitude of things to make Flatpaks an even stronger technology going forward.
Christian Hergert is working on figuring out how applications that require system daemons will work with Flatpaks, using his own Sysprof project as the proof of concept application. The general idea here is to rely on the work that has happened in SystemD around sysext/confext/portablectl trying to figure out who we can get a system service installed from a Flatpak and the necessary bits wired up properly.
The other part of this work, figuring out how to give applications permissions that today is handled with udev rules, that is being worked on by Hubert Figuière based on earlier work by Georges Stavracas on behalf of the GNOME Foundation thanks to the sponsorship from the Sovereign Tech Fund. So hopefully we will get both of these two important issues resolved soon.
Kalev Lember is working on polishing up the Flatpak support in Foreman (and Satellite) to ensure there are good tools for managing Flatpaks when you have a fleet of systems you manage, building on the work of Stephan Bergman.
Finally Jan Horak and Jan Grulich is working hard on polishing up the experience of using Firefox from a fully sandboxed Flatpak. This work is mainly about working with the upstream community to get some needed portals over the finish line and polish up some UI issues in Firefox, like this one.
Toolbx
Toolbx, our project for handling developer containers, is picking up pace with Debarshi Ray currently working on getting full NVIDIA binary driver support for the containers. One of our main goals for Toolbx atm is making it a great tool for AI development and thus getting the NVIDIA & CUDA support squared of is critical.
Debarshi has also spent quite a lot of time cleaning up the Toolbx website, providing easier access to and updating the documentation there.
We are also moving to use the new Ptyxis (formerly Prompt) terminal application created by Christian Hergert, in Fedora Workstation 40. This both gives us a great GTK4 terminal, but we also believe we will be able to further integrate Toolbx and Ptyxis going forward, creating an even better user experience.
Nova
So as you probably know, we have been the core maintainers of the Nouveau project for years, keeping this open source upstream NVIDIA GPU driver alive. We plan on keep doing that, but the opportunities offered by the availability of the new GSP firmware for NVIDIA hardware means we should now be able to offer a full featured and performant driver. But co-hosting both the old and the new way of doing things in the same upstream kernel driver has turned out to be counter productive, so we are now looking to split the driver in two. For older pre-GSP NVIDIA hardware we will keep the old Nouveau driver around as is. For GSP based hardware we are launching a new driver called Nova.
It is important to note here that Nova is thus not a competitor to Nouveau, but a continuation of it.
The idea is that the new driver will be primarily written in Rust, based on work already done in the community, we are also evaluating if some of the existing Nouveau code should be copied into the new driver since we already spent quite a bit of time trying to integrate GSP there. Worst case scenario, if we can’t reuse code, we use the lessons learned from Nouveau with GSP to implement the support in Nova more quickly.
Contributing to this effort from our team at Red Hat is Danilo Krummrich, Dave Airlie, Lyude Paul, Abdiel Janulgue and Phillip Stanner.
Explicit Sync and VRR
Another exciting development that has been a priority for us is explicit sync, which is critical for especially the NVidia driver, but which might also provide performance improvements for other GPU architectures going forward.
So a big thank you to Michel Dänzer , Olivier Fourdan, Carlos Garnacho; and Nvidia folks, Simon Ser and the rest of community for working on this. This work has just finshed upstream so we will look at backporting it into Fedora Workstaton 40.
Another major Fedora Workstation 40 feature is experimental support for Variable Refresh Rate or VRR in GNOME Shell. The feature was mostly developed by community member Dor Askayo, but Jonas Ådahl, Michel Dänzer, Carlos Garnacho and Sebastian Wick have all contributed with code reviews and fixes. In Fedora Workstation 40 you need to enable it using the command
gsettings set org.gnome.mutter experimental-features "['variable-refresh-rate']"
PipeWire
Already covered PipeWire in my post a week ago, but to quickly summarize here too. Using PipeWire for video handling is now finally getting to the stage where it is actually happening, both Firefox and OBS Studio now comes with PipeWire support and hopefully we can also get Chromium and Chrome to start taking a serious look at merging the patches for this soon. Whats more Wim spent time fixing Firewire FFADO bugs, so hopefully for our pro-audio community users this makes their Firewire equipment fully usable and performant with PipeWire. Wim did point out when I spoke to him though that the FFADO drivers had obviously never had any other consumer than JACK, so when he tried to allow for more functionality the drivers quickly broke down, so Wim has limited the featureset of the PipeWire FFADO module to be an exact match of how these drivers where being used by JACK. If the upstream kernel maintainer is able to fix the issues found by Wim then we could look at providing a more full feature set. In Fedora Workstation 40 the de-duplication support for v4l vs libcamera devices should work as soon as we update Wireplumber to the new 0.5 release.
Another major feature landing in Fedora Workstation 40 that Jonas Ådahl and Ray Strode has spent a lot of effort on is finalizing the remote desktop support for GNOME on Wayland. So there has been support for remote connections for already logged in sessions already, but with these updates you can do the login remotely too and thus the session do not need to be started already on the remote machine. This work will also enable 3rd party solutions to do remote logins on Wayland systems, so while I am not at liberty to mention names, be on the lookout for more 3rd party Wayland remoting software becoming available this year.
This work is also important to help Anaconda with its Wayland transition as remote graphical install is an important feature there. So what you should see there is Anaconda using GNOME Kiosk mode and the GNOME remote support to handle this going forward and thus enabling Wayland native Anaconda.
HDR
Another feature we been working on for a long time is HDR, or High Dynamic Range. We wanted to do it properly and also needed to work with a wide range of partners in the industry to make this happen. So over the last year we been contributing to improve various standards around color handling and acceleration to prepare the ground, work on and contribute to key libraries needed to for instance gather the needed information from GPUs and screens. Things are coming together now and Jonas Ådahl and Sebastian Wick are now going to focus on getting Mutter HDR capable, once that work is done we are by no means finished, but it should put us close to at least be able to start running some simple usecases (like some fullscreen applications) while we work out the finer points to get great support for running SDR and HDR applications side by side for instance.
PyTorch
We want to make Fedora Workstation a great place to do AI development and testing. First step in that effort is packaging up PyTorch and making sure it can have working hardware acceleration out of the box. Tom Rix has been leading that effort on our end and you will see the first fruits of that labor in Fedora Workstation 40 where PyTorch should work with GPU acceleration on AMD hardware (ROCm) out of the box. We hope and expect to be able to provide the same for NVIDIA and Intel graphics eventually too, but this is definitely a step by step effort.
The GStreamer team is pleased to announce another bug fix release
in the new stable 1.24 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.24.0.
Highlighted bugfixes:
Fix instant-EOS regression in audio sinks in some cases when volume is 0
rtspsrc: server compatibility improvements and ONVIF trick mode fixes
rtsp-server: fix issues if RTSP media was set to be both shared and reusable
(uri)decodebin3 and playbin3 fixes
adaptivdemux2/hlsdemux2: Fix issues with failure updating playlists
mpeg123 audio decoder fixes
v4l2codecs: DMA_DRM caps support for decoders
va: various AV1 / H.264 / H.265 video encoder fixes
vtdec: fix potential deadlock regression with ProRes playback
gst-libav: fixes for video decoder frame handling, interlaced mode detection
avenc_aac: support for 7.1 and 16 channel modes
glimagesink: Fix the sink not always respecting preferred size on macOS
gtk4paintablesink: Fix scaling of texture position
webrtc: Allow resolution and framerate changes, and many other improvements
webrtc: Add new LiveKit source element
Fix usability of binary packages on arm64 iOS
various bug fixes, build fixes, memory leak fixes, and other stability and reliability improvements
The GStreamer team is pleased to announce another bug fix release
in the now old-stable 1.22 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.22.x.
Highlighted bugfixes:
Fix instant-EOS regression in audio sinks in some cases when volume is 0
rtspsrc: server compatibility improvements and ONVIF trick mode fixes
libsoup linking improvements on non-Linux platforms
va: improvements for intel i965 driver
wasapi2: fix choppy audio and respect ringbuffer buffer/latency time
rtsp-server file descriptor leak fix
uridecodebin3 fixes
various bug fixes, build fixes, memory leak fixes, and other stability and reliability improvements
It’s been a busy few several months, but now that we have some breathing
room, I wanted to take stock of what we have done over the last year or so.
This is a good thing for most people and companies to do of course, but being a
scrappy, (questionably) young organisation, it’s doubly important for us to
introspect. This allows us to both recognise our achievements and ensure that
we are accomplishing what we have set out to do.
One thing that is clear to me is that we have been lagging in writing about
some of the interesting things that we have had the opportunity to work on,
so you can expect to see some more posts expanding on what you find below, as
well as some of the newer work that we have begun.
(note: I write about our open source contributions below, but needless to say,
none of it is possible without the collaboration, input, and reviews of members of
the community)
WHIP/WHEP client and server for GStreamer
If you’re in the WebRTC world, you likely have not missed the excitement around
standardisation of HTTP-based signalling protocols, culminating in the
WHIP and
WHEP specifications.
Tarun has been driving our client and server
implementations for both these protocols, and in the process has been
refactoring some of the webrtcsink and webrtcsrc code to make it easier to
add more signaller implementations. You can find out more about this work in
his talk at GstConf 2023
and we’ll be writing more about the ongoing effort here as well.
Low-latency embedded audio with PipeWire
Some of our work involves implementing a framework for very low-latency audio
processing on an embedded device. PipeWire is a good fit for this sort of
application, but we have had to implement a couple of features to make it work.
It turns out that doing timer-based scheduling can be more CPU intensive than
ALSA period interrupts at low latencies, so we implemented an IRQ-based
scheduling mode for PipeWire. This is now used by default when a pro-audio
profile is selected for an ALSA device.
In addition to this, we also implemented rate adaptation for USB gadget devices
using the USB Audio Class “feedback control” mechanism. This allows USB gadget
devices to adapt their playback/capture rates to the graph’s rate without
having to perform resampling on the device, saving valuable CPU and latency.
There is likely still some room to optimise things, so expect to more hear on
this front soon.
This should be useful in various embedded devices that have both the hardware
and firmware to make use of this power-saving feature.
GStreamer LC3 encoder and decoder
Tarun wrote a GStreamer plugin implementing the LC3 codec
using the liblc3 library. This is the
primary codec for next-generation wireless audio devices implementing the
Bluetooth LE Audio specification. The plugin is upstream and can be used to
encode and decode LC3 data already, but will likely be more useful when the
existing Bluetooth plugins to talk to Bluetooth devices get LE audio support.
QUIC plugins for GStreamer
Sanchayan implemented a QUIC source and sink plugin in
Rust, allowing us to start experimenting with the next generation of network
transports. For the curious, the plugins sit on top of the Quinn
implementation of the QUIC protocol.
There is a merge request open
that should land soon, and we’re already seeing folks using these plugins.
AWS S3 plugins
We’ve been fleshing out the AWS S3 plugins over the years, and we’ve added a
new awss3putobjectsink. This provides a better way to push small or sparse
data to S3 (subtitles, for example), without potentially losing data in
case of a pipeline crash.
We’ll also be expecting this to look a little more like multifilesink,
allowing us to arbitrary split up data and write to S3 directly as multiple
objects.
Update to webrtc-audio-processing
We also updated the webrtc-audio-processing
library, based on more recent upstream libwebrtc. This is one of those things
that becomes surprisingly hard as you get into it — packaging an API-unstable
library correctly, while supporting a plethora of operating system and
architecture combinations.
Clients
We can’t always speak publicly of the work we are doing with our clients, but
there have been a few interesting developments we can (and have spoken about).
Both Sanchayan and I spoke a bit about our work with WebRTC-as-a-service
provider, Daily. My talk at the GStreamer Conference
was a summary of the work I wrote about previously
about what we learned while building Daily’s live streaming, recording, and
other backend services. There were other clients we worked with during the
year with similar experiences.
Sanchayan spoke about the interesting approach to building
SIP support
that we took for Daily. This was a pretty fun project, allowing us to build a
modern server-side SIP client with GStreamer and SIP.js.
An ongoing project we are working on is building AES67 support using GStreamer
for FreeSWITCH, which essentially allows
bridging low-latency network audio equipment with existing SIP and related
infrastructure.
As you might have noticed from previous sections, we are also working on a
low-latency audio appliance using PipeWire.
Retrospective
All in all, we’ve had a reasonably productive 2023. There are things I know we
can do better in our upstream efforts to help move merge requests and issues,
and I hope to address this in 2024.
We have ideas for larger projects that we would like to take on. Some of these
we might be able to find clients who would be willing to pay for. For the ideas
that we think are useful but may not find any funding, we will continue to
spend our spare time to push forward.
If you made this this far, thank you, and look out for more updates!
Then this week OBS Studio shipped with PipeWire camera support thanks to the great work of Georges Stavracas, who cleaned up the patches and pushed to get them merged based on earlier work by himself, Wim Taymans and Colulmbarius. This means we now have two major applications out there that can use PipeWire for camera handling and thus two applications whose video streams that can be interacted with through patchbay applications like Helvum and qpwgraph.
These applications are important and central enough that having them use PipeWire are in itself useful, but they will now also provide two examples of how to do it for application developers looking at how to add PipeWire camera support to their own applications; there is no better documentation than working code.
The PipeWire support is also paired with camera portal support. The use of the portal also means we are getting closer to being able to fully sandbox media applications in Flatpaks which is an important goal in itself. Which reminds me, to test out the new PipeWire support be sure to grab the official OBS Studio Flatpak from Flathub.
PipeWire camera handling with OBS Studio, Firefox and Helvum.
Let me explain what is going on in the screenshot above as it is a lot. First of all you see Helvum there on the right showning all the connections made through PipeWire, both the audio and in yellow, the video. So you can see how my Logitech BRIO camera is feeding a camera video stream into both OBS Studio and Firefox. You also see my Magewell HDMI capture card feeding a video stream into OBS Studio and finally gnome-shell providing a screen capture feed that is being fed into OBS Studio. On the left you see on the top Firefox running their WebRTC test app capturing my video then just below that you see the OBS Studio image with the direct camera feed on the top left corner, the screencast of Firefox just below it and finally the ‘no signal’ image is from my HDMI capture card since I had no HDMI device connected to it as I was testing this.
The PipeWire support is of course fresh and I am sure we will find bugs and corner cases that needs fixing as more people test out the functionality in both Firefox and OBS Studio and there are some interface annoyances we are working to resolve. For instance since PipeWire support both V4L and libcamera as a backend you do atm get double entries in your selection dialogs for most of your cameras. Wireplumber has implemented de-deplucation code which will ensure only the libcamera listing will show for cameras supported by both v4l and libcamera, but is only part of the development version of Wireplumber and thus it will land in Fedora Workstation 40, so until that is out you will have to deal with the duplicate options.
Camera selection dialog
We are also trying to figure out how to better deal with infraread cameras that are part of many modern webcams. Obviously you usually do not want to use an IR camera for your video calls, so we need to figure out the best way to identify them and ensure they are clearly marked and not used by default.
Another recent good PipeWire new tidbit that became available with the PipeWire 1.0.4 release PipeWire maintainer Wim Taymans also fixed up the FireWire FFADO support. The FFADO support had been in there for some time, but after seeing Venn Stone do some thorough tests and find issues we decided it was time to bite the bullet and buy some second hand Firewire hardware for Wim to be able to test and verify himself.
Focusrite firewire device
.
Once the Focusrite device I bought landed at Wims house he got to work and cleaned up the FFADO support and make it both work and be performant.
For those unaware FFADO is a way to use Firewire devices without going through ALSA and is popular among pro-audio folks because it gives lower latencies. Firewire is of course a relatively old technology at this point, but the audio equipment is still great and many audio engineers have a lot of these devices, so with this fixed you can plop a Firewire PCI card into your PC and suddenly all those old Firewire devices gets a new lease on life on your Linux system. And you can buy these devices on places like ebay or facebook marketplace for a fraction of their original cost. In some sense this demonstrates the same strength of PipeWire as the libcamera support, in the libcamera case it allows Linux applications a way to smoothly transtion to a new generation of hardware and in this Firewire case it allows Linux applications to keep using older hardware with new applications.
So all in all its been a great few weeks for PipeWire and for Linux Audio AND Video, and if you are an application maintainer be sure to look at how you can add PipeWire camera support to your application and of course get that application packaged up as a Flatpak for people using Fedora Workstation and other distributions to consume.
The GStreamer team is excited to announce a new major feature release of
your favourite cross-platform multimedia framework!
As always, this release is again packed with new features, bug fixes and many other improvements.
The 1.24 release series adds new features on top of the previous 1.22 series
and is part of the API and ABI-stable 1.x release series of the GStreamer
multimedia framework.
Highlights:
New Discourse forum and Matrix chat space
New Analytics and Machine Learning abstractions and elements
Playbin3 and decodebin3 are now stable and the default in gst-play-1.0, GstPlay/GstPlayer
The va plugin is now preferred over gst-vaapi and has higher ranks
GstMeta serialization/deserialization and other GstMeta improvements
New GstMeta for SMPTE ST-291M HANC/VANC Ancillary Data
New unixfd plugin for efficient 1:N inter-process communication on Linux
cudaipc source and sink for zero-copy CUDA memory sharing between processes
New intersink and intersrc elements for 1:N pipeline decoupling within the same process
Qt5 + Qt6 QML integration improvements including qml6glsrc, qml6glmixer, qml6gloverlay, and qml6d3d11sink elements
DRM Modifier Support for dmabufs on Linux
OpenGL, Vulkan and CUDA integration enhancements
Vulkan H.264 and H.265 video decoders
RTP stack improvements including new RFC7273 modes and more correct header extension handling in depayloaders
WebRTC improvements such as support for ICE consent freshness, and a new webrtcsrc element to complement webrtcsink
WebRTC signallers and webrtcsink implementations for LiveKit and AWS Kinesis Video Streams
WHIP server source and client sink, and a WHEP source
Precision Time Protocol (PTP) clock support for Windows and other additions
Low-Latency HLS (LL-HLS) support and many other HLS and DASH enhancements
New W3C Media Source Extensions library
Countless closed caption handling improvements including new cea608mux and cea608tocea708 elements
Translation support for awstranscriber
Bayer 10/12/14/16-bit depth support
MPEG-TS support for asynchronous KLV demuxing and segment seeking, plus various new muxer features
Capture source and sink for AJA capture and playout cards
SVT-AV1 and VA-API AV1 encoders, stateless AV1 video decoder
New uvcsink element for exporting streams as UVC camera
DirectWrite text rendering plugin for windows
Direct3D12-based video decoding, conversion, composition, and rendering
AMD Advanced Media Framework AV1 + H.265 video encoders with 10-bit and HDR support
AVX/AVX2 support and NEON support on macOS on Apple ARM64 CPUs via new liborc
GStreamer C# bindings have been updated
Rust bindings improvements and many new and improved Rust plugins
Lots of new plugins, features, performance improvements and bug fixes
The GStreamer team is pleased to announce another release of liborc,
the Optimized Inner Loop Runtime Compiler, which is used for SIMD acceleration
in GStreamer plugins such as audioconvert, audiomixer, compositor, videoscale,
and videoconvert, to name just a few.
This is a minor bug-fix release which fixes an issue on x86 architectures
with hardened Linux kernels.
Highlights:
x86: account for XSAVE when checking for AVX support, fixing usage on hardened linux kernels where AVX support has been disabled
neon: Use the real intrinsics for divf and sqrtf
orc.m4 for autotools is no longer shipped. If anyone still uses it they can copy it into their source tree
The GStreamer team is excited to announce the first release candidate
for the upcoming stable 1.24.0 feature release.
This 1.23.90 pre-release is for testing and development purposes
in the lead-up to the stable 1.24 series which is now frozen for
commits and scheduled for release very soon.
Depending on how things go there might be more release candidates in
the next couple of days, but in any case we're aiming to get 1.24.0 out
as soon as possible.
Preliminary release notes highlighting all the new features, bugfixes,
performance optimizations and other important changes will be available
in the next few days.
Binaries for Android, iOS, Mac OS X and Windows will be made available shortly
at the usual location.
The GStreamer team is pleased to announce another development release in
the unstable 1.23 release series.
The unstable 1.23 release series is for testing and development purposes in
the lead-up to the stable 1.24 series which is scheduled for release ASAP.
Any newly-added API can still change until that point.
Full release notes will be provided in the near future, highlighting all the
new features, bugfixes, performance optimizations and other important changes.
This development release is primarily for developers and early adopters.
Binaries for Android, iOS, Mac OS X and Windows will be made available shortly
at the usual location.
The GStreamer team is pleased to announce another bug fix release
in the stable 1.22 release series of your favourite cross-platform
multimedia framework!
This release only contains bugfixes and security fixes and it should be safe
to update from 1.22.x.
Highlighted bugfixes:
gst-python: fix bindings overrides for Python >= 3.12
glcolorconvert: fix wrong RGB to YUV matrix with bt709
glvideoflip: fix "method" property setting at construction time
gtk4paintablesink: Always draw a black background behind the video frame, and other fixes
pad: keep segment event seqnums the same when applying a pad offset
basesink: Preroll on out of segment buffers when not dropping them
Prefer FFmpeg musepack decoder/demuxer, fixing musepack playback in decodebin3/playbin3
livesync: add support for image formats such as JPEG or PNG
sdpdemux: Add SDP message (aka session) attributes to the caps too
textwrap: add support for gaps
macos: Fix gst_macos_main() terminating whole process, and set activation policy
webrtcbin: Improve SDP intersection for Opus
various bug fixes, build fixes, memory leak fixes, and other stability and reliability improvements
I know, it’s old news, but still, I was pending to write about the GstVA
library to
clarify its purpose and scope.I didn’t want to have a library for GstVA, because to maintain a library is a
though duty. I learnt it in the bad way with GStreamer-VAAPI. Therefore, I
wanted GstVA as simple as possible, direct in its
libva usage, and self-contained.
As far as I know, the main usage of GStreamer-VAAPI library was to have access
to the VASurface from the GstBuffer, for example, with appsink. Since the
beginning of GstVA, a mechanism to access the surface ID was provided, as
`GStreamer OpenGL** offers access to the texture ID: through a flag when
mapping
a GstGL
memory
backed buffer. You can see how this mechanism is used in the one of the GstVA
sample
apps.
Nevertheless, later another use case appeared which demanded a library for
GstVA: Other GStreamer elements needed to produce or consume VA surface backed
buffers. Or to say it more concretely: they needed to use the GstVA allocator
and buffer pool, and the mechanism to share the GstVA context along the pipeline
too. The plugins with those VA related elements are
msdk and
qsv, when they
operate on Linux. Both elements use Intel
OneVPL,
so they are basically competitors. The main difference is that the first is
maintained by Intel, and has more features, specially for Linux, whilst the
former in maintained by Seungha Yang, and it
appears to be better tested in Windows.
These are the objects exposed by the GstVA library API:
GstVaDisplay
represents a
VADisplay,
the interface between the application and the hardware accelerator. This class
is abstract, and it’s supposed not to be instantiated. Instantiation has to go
through it derived classes, such as
GstVaDisplayWrapped,
for user-injected display connections, for example, VA X11 or Wayland
connection, through the
GstContext
bus message GST_MESSAGE_NEED_CONTEXT. See the mentioned
example.
The experimental VA backend for
Windows:
GstVaDisplayWin32, merged for the next release 1.24.
This class is shared among all the elements in the pipeline via GstContext, so
all the plugged elements share the same connection the hardware accelerator.
Unless the plugged element in the pipeline has a specific name, as in the
case of multi GPU systems.
Let’s talk a bit about multi GPU systems. This is the gst-inspect-1.0 output
of a system with an Intel and an AMD GPU, both with VA support:
$gst-inspect-1.0 va Plugin Details: Name va Description VA-API codecs plugin Filename /home/igalia/vjaquez/gstreamer/build/subprojects/gst-plugins-bad/sys/va/libgstva.so Version 1.23.1.1 License LGPL Source module gst-plugins-bad Documentation https://gstreamer.freedesktop.org/documentation/va/ Binary package GStreamer Bad Plug-ins git Origin URL Unknown package origin
vaav1dec: VA-API AV1 Decoder in Intel(R) Gen Graphics vacompositor: VA-API Video Compositor in Intel(R) Gen Graphics vadeinterlace: VA-API Deinterlacer in Intel(R) Gen Graphics vah264dec: VA-API H.264 Decoder in Intel(R) Gen Graphics vah264lpenc: VA-API H.264 Low Power Encoder in Intel(R) Gen Graphics vah265dec: VA-API H.265 Decoder in Intel(R) Gen Graphics vah265lpenc: VA-API H.265 Low Power Encoder in Intel(R) Gen Graphics vajpegdec: VA-API JPEG Decoder in Intel(R) Gen Graphics vampeg2dec: VA-API Mpeg2 Decoder in Intel(R) Gen Graphics vapostproc: VA-API Video Postprocessor in Intel(R) Gen Graphics varenderD129av1dec: VA-API AV1 Decoder in AMD Radeon Graphics in renderD129 varenderD129av1enc: VA-API AV1 Encoder in AMD Radeon Graphics in renderD129 varenderD129compositor: VA-API Video Compositor in AMD Radeon Graphics in renderD129 varenderD129deinterlace: VA-API Deinterlacer in AMD Radeon Graphics in renderD129 varenderD129h264dec: VA-API H.264 Decoder in AMD Radeon Graphics in renderD129 varenderD129h264enc: VA-API H.264 Encoder in AMD Radeon Graphics in renderD129 varenderD129h265dec: VA-API H.265 Decoder in AMD Radeon Graphics in renderD129 varenderD129h265enc: VA-API H.265 Encoder in AMD Radeon Graphics in renderD129 varenderD129jpegdec: VA-API JPEG Decoder in AMD Radeon Graphics in renderD129 varenderD129postproc: VA-API Video Postprocessor in AMD Radeon Graphics in renderD129 varenderD129vp9dec: VA-API VP9 Decoder in AMD Radeon Graphics in renderD129 vavp9dec: VA-API VP9 Decoder in Intel(R) Gen Graphics
22 features: +-- 22 elements
As you can observe, each card registers the supported element. The first GPU, the
Intel one, doesn’t insert renderD129 after the va prefix, while the AMD
Radeon, does. As you could imagine, renderD129 is the device name in
/dev/dri:
The appended device name expresses the DRM device the elements use. And only
after the second GPU the device name is appended. This allows to use the
untagged elements either for the first GPU or to allow the usage of a wrapped
display injected by the user application, such as VA X11 or Wayland connections.
Notice that sharing DMABuf-based buffers between different GPUs is theoretically
possible, but not assured.
Keep in mind that, currently,
nvidia-vaapi-driver is not
supported by GstVA, and the driver will be ignored by the plugin register since
1.24.
VA surface
allocator.
It allocates a
GstMemory
that wraps a VASurfaceID, which represents a complete frame directly
consumable by VA-based elements. Thus, a
GstBuffer
will hold one and only one GstMemory of this type. These buffers are the
very same used by the system memory buffers, since the surfaces generally can
map their content to CPU memory (unless they are encrypted, but GstVA haven’t
been tested for that use case).
VA-DMABuf
allocator.
It descends from
GstDmaBufAllocator,
though it’s not an allocator in strict sense, since it only imports DMABufs to
VA surfaces, and exports VA surfaces to DMABufs. Notice that a single VA
surface can be exported as multiple DMABuf-backed GstMemories, and the
contrary, a VA surface can be imported from multiple DMABufs.
One particularity of both allocators is that they keep an internal pool of the
allocated VA surfaces, since the mapping of buffers/memories is not always 1:1,
as in the case of DMABuf; to reuse surfaces even if the buffer pool ditches
them, and to avoid surface leaks, keeping track of them all the time.
This class is only useful for other GStreamer elements capable of consume VA
surfaces, so they could instantiate, configure and propose a VA buffer pool, but
not for applications.
And that’s all for now. Thank you for bear with me up to here. But remember,
the API of the library is unstable, and it can change any time. So, no promises
are made :)
I recently replaced my Flashforge Adventurer 3 printer that I had been using for a few years as my first printer with a BambuLab X1 Carbon, wanting a printer that was not a “project” so I could focus on modelling and printing. It's an investment, but my partner convinced me that I was using the printer often enough to warrant it, and told me to look out for Black Friday sales, which I did.
The hardware-specific slicer, Bambu Studio, was available for Linux, but only as an AppImage, with many people reporting crashes on startup, non-working video live view, and other problems that the hardware maker tried to work-around by shipping separate AppImage variants for Ubuntu and Fedora.
After close to 150 patches to the upstream software (which, in hindsight, I could probably have avoided by compiling the C++ code with LLVM), I manage to “flatpak” the application and make it available on Flathub. It's reached 3k installs in about a month, which is quite a bit for a niche piece of software.
Note that if you click the “Donate” button on the Flathub page, it will take you a page where you can feed my transformed fossil fuel addiction buy filament for repairs and printing perfectly fitting everyday items, rather than bulk importing them from the other side of the planet.
I will continue to maintain the FlashPrint slicer for FlashForge printers, installed by nearly 15k users, although I enabled automated updates now, and will not be updating the release notes, which required manual intervention.
FlashForge have unfortunately never answered my queries about making this distribution of their software official (and fixing the crash when using a VPN...).
Rhythmbox
As I was updating the Rhythmbox Flatpak on Flathub, I realised that it just reached 250k installs, which puts the number of installations of those 3D printing slicers above into perspective.
The updated screenshot used on Flathub
Congratulations, and many thanks, to all the developers that keep on contributing to this very mature project, especially Jonathan Matthew who's been maintaining the app since 2008.
The GStreamer team is pleased to announce the first development release in
the unstable 1.23 release series.
The unstable 1.23 release series is for testing and development purposes in
the lead-up to the stable 1.24 series which is scheduled for release ASAP.
Any newly-added API can still change until that point.
This development release is primarily for developers and early adopters.
Binaries for Android, iOS, Mac OS X and Windows will be made available shortly
at the usual location.
The GStreamer team is pleased to announce another release of liborc,
the Optimized Inner Loop Runtime Compiler, which is used for SIMD acceleration
in GStreamer plugins such as audioconvert, audiomixer, compositor, videoscale,
and videoconvert, to name just a few.
This is a bug-fix release that fixes some recent regressions, but also
properly enables liborc on Apple arm64 devices.
Highlights:
Apple arm64 enablement
macOS/iOS fixes
orcc regression fix, would default to "sse" backend
I attended FOSDEM last weekend and had the pleasure to participate in the Flathub / Flatpak BOF on Saturday. A lot of the session was used up by an extensive discussion about the merits (or not) of allowing direct uploads versus building everything centrally on Flathub’s infrastructure, and related concerns such as automated security/dependency scanning.
My original motivation behind the idea was essentially two things. The first was to offer a simpler way forward for applications that use language-specific build tools that resolve and retrieve their own dependencies from the internet. Flathub doesn’t allow network access during builds, and so a lot of manual work and additional tooling is currently needed (see Python and Electron Flatpak guides). And the second was to offer a maybe more familiar flow to developers from other platforms who would just build something and then run another command to upload it to the store, without having to learn the syntax of a new build tool. There were many valid concerns raised in the room, and I think on reflection that this is still worth doing, but might not be as valuable a way forward for Flathub as I had initially hoped.
Of course, for a proprietary application where Flathub never sees the source or where it’s built, whether that binary is uploaded to us or downloaded by us doesn’t change much. But for an FLOSS application, a direct upload driven by the developer causes a regression on a number of fronts. We’re not getting too hung up on the “malicious developer inserts evil code in the binary” case because Flathub already works on the model of verifying the developer and the user makes a decision to trust that app – we don’t review the source after all. But we do lose other things such as our infrastructure building on multiple architectures, and visibility on whether the build environment or upload credentials have been compromised unbeknownst to the developer.
There is now a manual review process for when apps change their metadata such as name, icon, license and permissions – which would apply to any direct uploads as well. It was suggested that if only heavily sandboxed apps (eg no direct filesystem access without proper use of portals) were permitted to make direct uploads, the impact of such concerns might be somewhat mitigated by the sandboxing.
However, it was also pointed out that my go-to example of “Electron app developers can upload to Flathub with one command” was also a bit of a fiction. At present, none of them would pass that stricter sandboxing requirement. Almost all Electron apps run old versions of Chromium with less complete portal support, needing sandbox escapes to function correctly, and Electron (and Chromium’s) sandboxing still needs additional tooling/downstream patching to run inside a Flatpak. Buh-boh.
I think for established projects who already ship their own binaries from their own centralised/trusted infrastructure, and for developers who have understandable sensitivities about binary integrity such such as encryption, password or financial tools, it’s a definite improvement that we’re able to set up direct uploads with such projects with less manual work. There are already quite a few applications – including verified ones – where the build recipe simply fetches a binary built elsewhere and unpacks it, and if this already done centrally by the developer, repeating the exercise on Flathub’s server adds little value.
However for the individual developer experience, I think we need to zoom out a bit and think about how to improve this from a tools and infrastructure perspective as we grow Flathub, and as we seek to raise funds for different sources for these improvements. I took notes for everything that was mentioned as a tooling limitation during the BOF, along with a few ideas about how we could improve things, and hope to share these soon as part of an RFP/RFI (Request For Proposals/Request for Information) process. We don’t have funding yet but if we have some prospective collaborators to help refine the scope and estimate the cost/effort, we can use this to go and pursue funding opportunities.
switcheroo-control got picked up by Jonas Ådahl, one of the mutter maintainers. I'm looking forward to seeing this merge request fixed so we can have better menu items on dual-GPU systems
iio-sensor-proxy added Dylan Van Assche to its maintenance team, assisting Guido Günther.
(As an aside, there's posturing towards replacing power-profiles-daemon with tuned in Fedora. I would advise stakeholders to figure out whether having a large Python script in the boot hot path is a good idea, taking a look at bootcharts, and then thinking about whether hardware manufacturers would be able to help with supporting a tool with so many moving parts. Useful for tinkering, not for shipping in a product)
Updated responsibilities
Since mid-August, I've joined the Platform Enablement Team. Right now, I'm helping out with maintenance of the Bluetooth kernel stack in RHEL (and thus CentOS).
The goal is to eventually pivot to hardware enablement, which is likely to involve backporting and testing, more so than upstream enablement. This is currently dependent on attending some formal kernel development (and debugging) training sessions which should make it easier to see where my hodge-podge kernel knowledge stands.
Blog backlog
Before being moved to a different project, and apart from the usual and very time-consuming bug triage, user support and project maintenance, I also worked on a few new features. I have a few posts planned that will lay that out.
The GStreamer team is pleased to announce another release of liborc,
the Optimized Inner Loop Runtime Compiler, which is used for SIMD acceleration
in GStreamer plugins such as audioconvert, audiomixer, compositor, videoscale,
and videoconvert, to name just a few.
This is a bug-fix release that fixes a regression introduced by the
recent 0.4.35 release, fixing a crash on machines that only support AVX
but not AVX2.
Highlights:
Only use AVX / AVX2 instructions on CPUs that support both AVX and AVX2